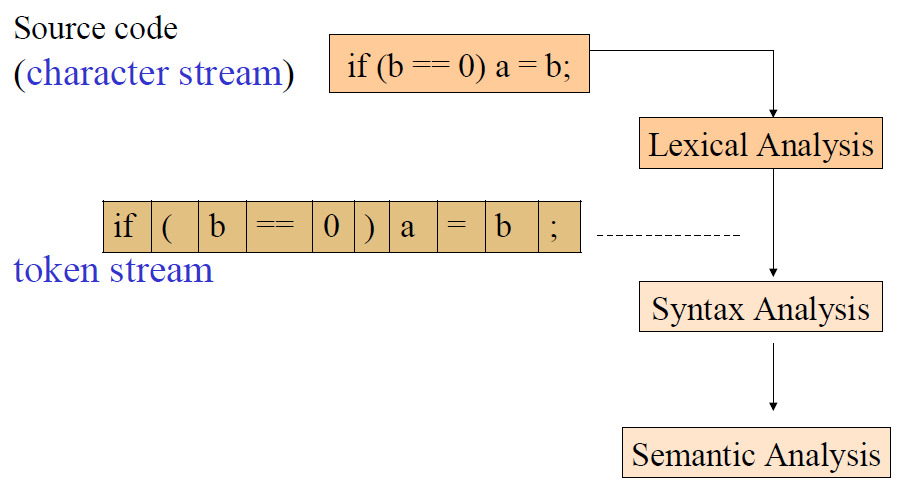
Scanning Process
- Identifier: x y11 elsen_i00
- Integer: 2 1000 -500 5L
- Floating point: 2.0 0.00020 .02 1. 1e5 0.e-10
- String: “x” “He said, \“Are you?\””
- Comment: / don’t change this /
- Keyword: if else while break
- Symbol: + * { } ++ < << [ ] >=
正则表达式(Regular Expression, RE)
定义
通过递归定义

其中运算的优先级:alternation < concatenation < repetition(R*)
RE的表达形式不唯一
RE不可计数(不可记忆)
eg.

Regular Set: RE 的集合(正规表达式封闭)
语法
R+: one or more strings from L(R):R(R*)R?: optional R(一次或零次):(R|ε)[abce]: one of the listed characters:(a|b|c|e)[a-z]: one character from this range:(a|b|c|d|e|…|y|z)eg. [A-Z a-z]表示包含大小写的所有字母
[^ab]: anything but one of the listed chars[^a-z]: one character not from this range
示例
Numbers
自然数:nat = [0-9]+
有符号自然数:signedNat = (+|-)?nat
实数(可能包含小数点or科学计数法):number = signedNat(“.”” nat)? (E signedNat)?Reserved Words and Identifiers
保留字(一般枚举表示):reserved = if | while | do |………
字母:letter = [a-z A-Z]
数字:digit = [0-9]
标识符:identifier = letter (letter | digit)*$reserved \subset iderntifier$
Comment

一些原则
处理歧义
keyword优先
如果一个标识符可以是keyword,就优先认为它是keyword(如if)
最长子串匹配
如果能被当成是一个identifier,就不会当成多个(例如iff,可以是iff或者if+f,认为是iff)
明确认为属于其他标记作为分隔符
空白符
用于分割,没有返回
whitespace = ( newline | blank | tab | comment )+
Lookahead
缓冲区内可能存在下一个输入的符号,要标记回溯位置
有限自动机(Finite Automata, FA)
状态个数有限
state 可以重复
transition:标记两个状态之间的转换
start state:开始状态前要加无标签箭头
- accepting state:用双环表示接收(结束)状态(单环表示非接收状态),转换可以到接收态结束
有的状态不接受一些字符,即接收了会进入error state,可以不在图中表示出来
确定型有限自动机(Deterministic Finite Automation, DFA)
状态转移目标确定(唯一)
状态转移时接收一个符号(可以用名字表示)
$T:S \times \sum \rightarrow S$,$T(s,c)$ 必须对每一个s和c都有值(error state可以不画在图中)
Typical action
- making an transition:从输入缓冲区得到字符,得到字符串(字符串值或者词义)
- reaching an accepting state:将token和相关属性(字符串内容、数字值等)返回给词法分析器
- reaching an error state:回退(之前分析的可能不对)或者生成error token
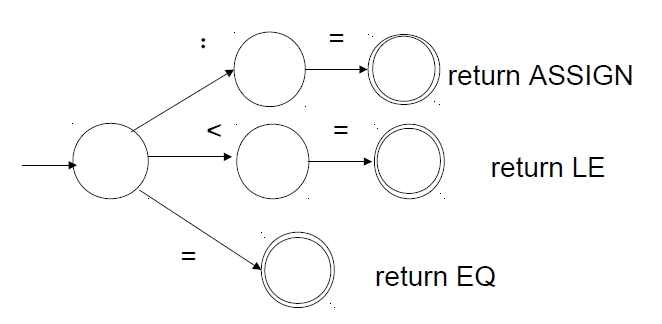
eg.
非确定型有限自动机(Nondeterministic Finite Automaton, NFA)
NFA与DFA功能等价,可以相互转换
主要区别在于,NFA有 $\epsilon - transition$(不消耗输入的转移)
$\epsilon - transition$ 的两个主要作用:
- 选择功能(不用合并新来的状态,而是增加一个新的状态)
- 匹配外部输入的空串
NFA的定义包括转换关系(不一定是函数)T、开始状态s0、接收状态A、接受语言L(M)
表达比较灵活,可以有变数(与之对应的是,可能会影响分析效率)
【IMPORTANT】从RE到DFA的转换

RE -> NFA
Top-down
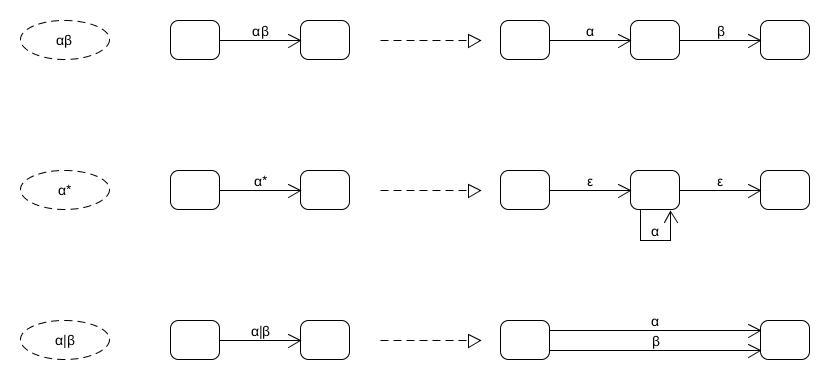
Thompson’s construction (Bottom-up)
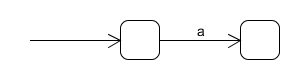
对于单个字符,构造一个如下图所示的转换图,作为一个单元:
在遇到操作符时,所有的处理都针对单元(在下图上用虚线圈表示):
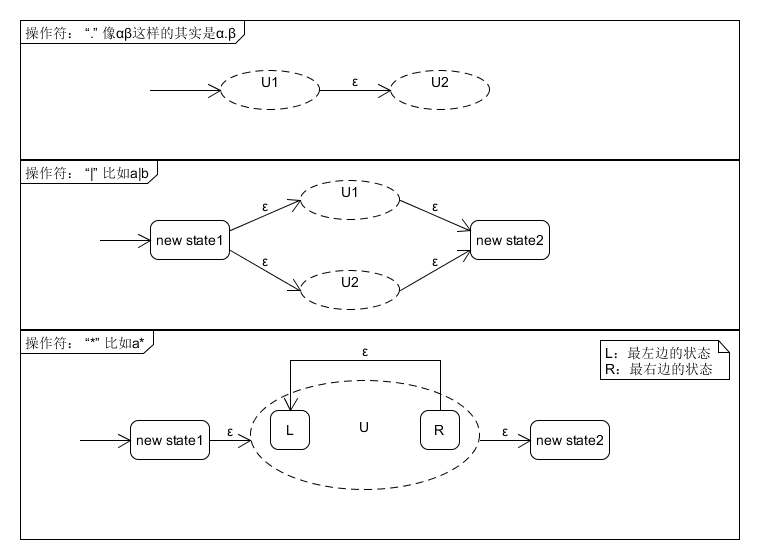
在处理完操作符之后,形成新的单元,然后继续下一次处理(类似递归),直到转换为NFA
NFA -> DFA
- 先得到每个状态对应的$\epsilon$闭包(当前状态下能够通过$\epsilon$推出的所有状态的集合,先找出该状态的ε边推出的所有状态,再找那些状态的ε边推出的状态,是一个迭代的过程,直到找出一个状态的ε闭包)
- 以原NFA的start state作为DFA的start state,对于当前状态中的每一个子状态,对每一个符号做一次推出操作,构造新的状态和推出过程(注意推出的是NFA对应状态的ε闭包,展开求并得到新的状态)
- 重复2直到没有新的状态或转换被创建
- DFA中,包含了NFA中accept state的都是accept state
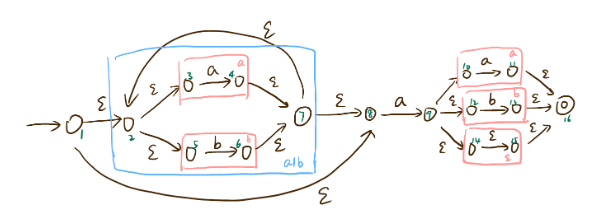
举个栗子便于理解:
$(a|b)^*a(a|b|ε)$
得到NFA如下图:
对各状态求ε闭包:
$\overline 1 = {1,2,3,5,8}$
$\overline 2 = {2,3,5}$
$\overline 3 = {3}$
$\overline 4 = {2,3,4,5,7,8}$
$\overline 5 = {5}$
$\overline 6 = {2,3,5,6,7,8}$
$\overline 7 = {2,3,5,7,8}$
$\overline 8 = {8}$
$\overline 9 = {9,10,12,14,15,16}$
$\overline{10} = {10}$
$\overline{11} = {11,16}$
$\overline{12} = {12}$
$\overline{13} = {13,16}$
$\overline{14} = {14,15,16}$
$\overline{15} = {15,16}$
$\overline{16} = {16}$得到新的状态转换表:
(例如,从S0中各状态通过a:3->4, 8->9,所以S0通过a转移到 {$\overline 4, \overline 9$},展开如表中所示,其他同理)
$S’$ $S’_a$ $S’_b$ S0 = {1,2,3,5,8} S1 = {2,3,4,5,7,8,9,10,12,14,15,16} S2 = {2,3,5,6,7,8} S1 = {2,3,4,5,7,8,9,10,12,14,15,16} S3 = {2,3,4,5,7,8,9,10,11,12,14,15,16} S4 = {2,3,5,6,7,8,13,16} S2 = {2,3,5,6,7,8} S1 = {2,3,4,5,7,8,9,10,12,14,15,16} S2 = {2,3,5,6,7,8} S3 = {2,3,4,5,7,8,9,10,11,12,14,15,16} S3 = {2,3,4,5,7,8,9,10,11,12,14,15,16} S4 = {2,3,5,6,7,8,13,16} S4 = {2,3,5,6,7,8,13,16} S3 = {2,3,4,5,7,8,9,10,11,12,14,15,16} S2 = {2,3,5,6,7,8} 画出DFA:
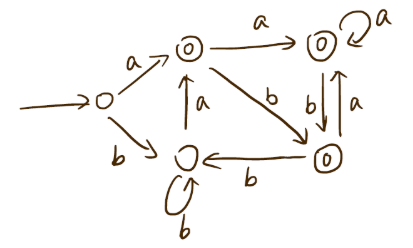
DFA的优化(最小化)
最小化的需求是,每个等价类只能由一个状态来表示,因此这一步要做的就是划分等价类
先根据是否为终止状态分为两类,非终止状态和终止状态
在每一类中继续细分,对等价类的要求是,对同一符号,转换到的新状态要属于同一等价类(注意,是同一等价类,可以是该等价类下不同的状态)。因此对于每一类中的每个子状态,对每一个符号进行转换,一旦有转换结果属于不同的类,则将其分在不同的等价类下。
- 对每一个类重复2,要注意的是,划分完后面的类之后,要回去看一下前面的类是否需要进一步划分(因为可能之前结果在同一类,但在后面被分开了)
- 每个等价类取一个状态作为代表,画新的DFA
上一个例子中简化的结果如下图:
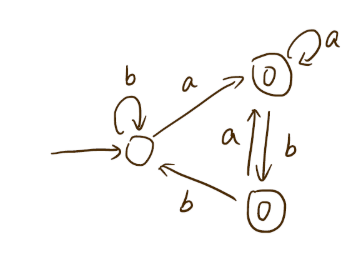
参考:here
Lex
input: a text file containing regular expressions, together with the actions to be taken when each expression is matched
output: Contains C source code defining a procedure yylex that is\
a table-driven implementation of a DFA corresponding to the regular expressions of the input file, and that operates like a getToken procedure.
The format of a Lex input file
{definitions} –> 定义
%% –> 分隔符
{rules} –> 核心
%%
{auxiliary routines} –> action中用到的函数等
Definitions
放在 %{…%} 的省略号部分中(遇到%不会处理,而是原封放入output)
RE的命名在这里会被定义(因为RE不唯一,命名之后可以用于简化)
Rules
将RE和将要运行的代码相对应(一对一关系,RE - action)
Auxiliary routines
函数定义
“.”可以用作通配符,匹配除换行符外的所有符号
1 | %{ |