语法分析树的结构取决于语言的结构,且是一种动态的数据结构(可以增、删、改)
Context-Free Grammar (CFG)
$RE ⊆ CFG$
产生式左边(LHS,left-hand sides)只有一个符号,且是非终结符
定义
A Context-Free Grammar is a 4-tuple $(V,Σ,S,→)$, where
- $V$ is a finite set of nonterminal symbols
- $Σ$ is a finite set of terminal symbols
- $S ∈ V $ is a distinguished nonterminal, the start symbol
- $→ ⊆ V × (V ∪ Σ)^* Σ)^*$ is a finite relation, the productions
更加正式的定义:
$G = (T,N,P,S)$
- $T$: Terminals
- $N$: Nonterminals (disjoint from T)
- $P$: Productions (Grammar rules), $A \rightarrow a,\;A \in N, \; a \in (T \cup N)^*$
- $S$: Start symbol ($S \in N$)
- sentencial from: a string in $(T \cup N)^*$
- sentence: $T^*$,只能由终结符组成
- $T \cup N$ 表示文法的所有符号
- $\alpha \Rightarrow^* \beta$ 表示$\alpha$可以通过 $n \; (n\geq 0)$ 步变换为$\beta$
- derivation: ${S \Rightarrow^* w} {\; (w \in T^*)}$
- $L(G)$: 由文法生成的语言,$L(G) = {w \in T^*\;|\;there \; exists \; a derivation\; S \Rightarrow^* w \; of \; G}$
- rightmost derivation: $S \Rightarrow_{rm}^* w $, $a A \gamma \Rightarrow a \beta \gamma, \, a \in T^*$
- leftmost derivation: $S \Rightarrow_{lm}^* w $, $a A \gamma \Rightarrow a \beta \gamma, \, \gamma \in T^*$
推导
BNF范式
通常用大写字母表示非终结符,用小写表示终结符
递归(recursion)
- 左递归:LHS的非终结符出现在RHS的第一个字符$A \rightarrow A \, \alpha \, | \, \beta$ 等价于 $(\beta\alpha^*)$
- 右递归:LHS的非终结符出现在RHS的最后一个字符$A \rightarrow \alpha \, A \, | \, \beta$ 等价于 $(\alpha^*\beta)$
$\alpha$、$\beta$是任意的串(终结符或非终结符都可),其中$\beta$不以$A$为开头/结尾
两者在很多情况下不等价
$\epsilon$ 产生式($\epsilon-production$)
$empty \, \rightarrow \, \epsilon$
用于产生空串,如果语言中要有空串,必须要有$\epsilon$ 产生式
如$a^*$相当于$A \rightarrow A \, \alpha \, | \, \epsilon \; or \; A \rightarrow \alpha \, A \, | \, \epsilon$
$\epsilon$ 作用:让文法更简洁,效率更高
eg. $A \rightarrow (A) \, A \,| \, \epsilon$,生成能够匹配的括号
正规表达式没有记忆功能,上下文无关语法可以
Parse Trees and Abstract Syntax Trees
Parse Trees
用树的形态来表示推导,推导和树是多对一的关系
非叶节点表示非终结符,叶节点表示终结符
最左推导(leftmost derivation):每次展开最左边的非终结符,对应parse tree的前序遍历
最右推导(rightmost derivation):每次展开最右边的非终结符,对应parse tree的后序遍历
每一棵树都只有唯一的最左推导和最右推导
eg.
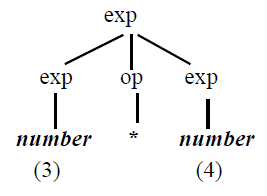
要注意的是在文法分析中关注的是类型而不是语义(因此parse tree的叶节点推出的是number而不是具体的3or4),词义在语义分析中进行处理
Abstract Syntax Trees
parse tree 的压缩版(更简洁)
用运算符/操作作为根节点和内部节点,操作数作为子节点
在树中不体现推导过程,只显示推导结果
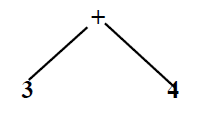
(+其实代表相加的结果)
eg.
parse tree:
syntax tree:

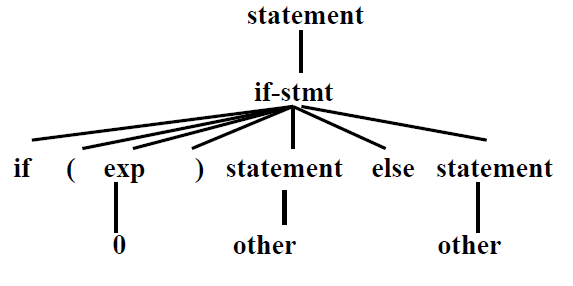
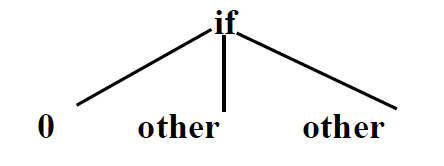
孩子个数可能不定,可以用leftmost-child right sibling来表达
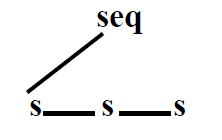
歧义(ambiguity)
一个可以构建两个不同结构的parse tree的语法具有歧义(可能会因为没有区分优先级和结合律造成)
符号离树根越远优先级越高
解决方法:
定义一个消除歧义的规则,例如指明哪一种tree是对的
优点:不需要改变原来的语法
缺点:文法结构并非只由语法来规定(grammar+rule)
改造文法,使得没有语法错误
缺点:改造文法可能会降低可读性(有时候为了简洁性,可能还是会选择保留原来有歧义的形态)
结合律:
- A left recursive rule makes its operators associate on the left.
- A right recursive rule makes them associate on the right.
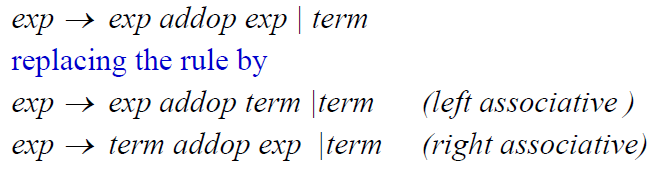
eg1.
会有歧义,因为没有规定*和+-的优先级,如34-3*42
改成规定*优先级更高之后可以消除歧义(但parse tree会变得更加复杂):
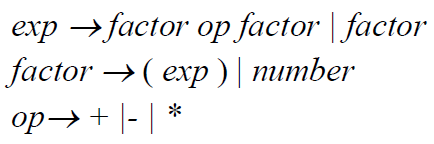
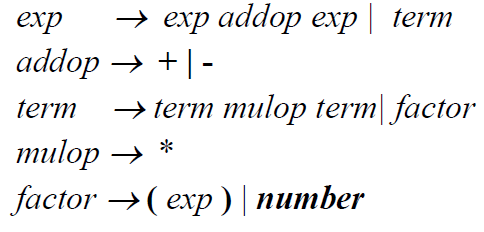
Dangling else problem
if语句的else匹配可能会带来歧义
C中引入了{}来消除歧义,在Ada中引入end if
在文法中,可以用类似以下的方法:
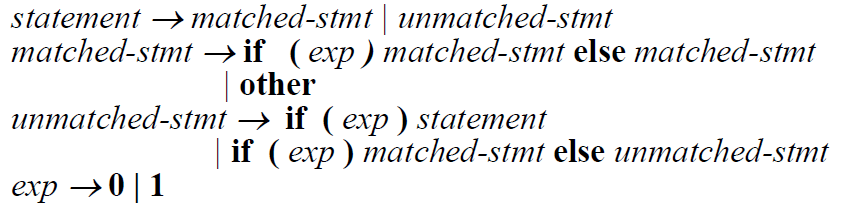
Ada的文法(用BNF表示)

Inessential ambiguity
有一些歧义无关紧要,具体得看语义
EBNF(Extended BNF)
在BNF基础上增加重复({…})和选择([],一次或零次)

