Recursive-Descent
不能出现左递归or间接左递归(因为左递归可能会造成无限循环)
左递归:A → A a | …
间接左递归:A → B b | .. , B → A a | …
BNF要被扩展为EBNF
eg. expr → expr addop term | term
EBNF: expr → term {addop term}
文法改造——消除左递归 / 提取左因子
消除左递归
Case 1: simple immediate left recursion
$A → Aα|β$
Rewrite:
$A → βA′$
$A′ → αA′|ε$
Case 2: general immediate left recursion
$A→Aα_1|Aα_2|⋯|Aα_n|β_1|β_2|⋯|β_m$
Rewrite:
$A→β_1A′|β_2A′|⋯|β_mA′$
$A′→α_1A′|α_2A′|⋯|α_nA′|ε$
Case 3: general left recursion
这里描述的算法仅是指不带有产生式且不带有循环的文法(其中循环是至少有一步是以相同的非终结符:$A \Rightarrow \alpha \Rightarrow^* A$开始和结束的推导。循环几乎肯定能导致分析程序进入无穷循环,而且带有循环的文法从不作为程序设计语言文法出现。程序设计语言文法确实是有产生式,但这经常是在非常有限的格式中,所以这个算法对于这些文法也几乎总是有效的。
该算法的方法是:为语言的所有非终结符选择任意顺序,如$A_1 , … , A_m$,接着再消除不增加$A_i’ $索引的所有左递归。它消除所有$A_i→A_j \gamma$,其中$j≤i$形式的规则。如果按这样操作从1到m的每一个i,则由于这样的循环的每个步骤只增加索引,且不能再次到达原始索引,因此就不会留下任何递归循环了。
1 | for i:=1 to m do |
eg.
A → B a | A a | c
B → B b | A b | d
remove the immediate left recursion of A
A → B a A’ | c A’
A’ → a A’ | ε
B → B b | A b| deliminate B → Ab by replacing A with its choices
A → B a A’ | c A’
A’ → a A’ | ε
B → B b | B a A‘ b | c A’ b | dremove the immediate left recursion of B
A → B a A’ | c A’
A’ → a A’ | ε
B → c A’ b B’ | d B’
B’ → b B’ | a A’ b B’ | ε
提取左因子
当两个或更多文法规则选择共享一个通用前缀串时,需要提取左因子(因为lookahead是1的时候如果有两条产生式将不知道应该走哪条。
如 A → αβ|αγ $\Rightarrow$ A → α A’, A’ → β|γ
if-stmt → if (exp) statement | if (exp) statement else statement
在这个文法中,提取了左因子的格式是
if-stmt → if (exp) statement else-part
else-part → else statement | ε
LL(1) Parsing
from Left to right
Left-most
look-ahead: 1 symbol (top-down必须至少look-ahead一个字符)
Definition
如果一个文法的LL(1)分析表中每一项最多只有一个产生式,则该文法是LL(1)文法(LL(1)文法不能有歧义)
Basic method
Two actions
- Generate:当分析栈顶是非终结符时,用文法$ A \rightarrow α$ 将A替换成α(注意:倒序进栈)
Match:栈顶是终结符时,将栈顶的符号和输入符号进行匹配
当分析栈和输入都为空时可以执行accept(代表文法分析顺利结束)
$ 表示栈底 / end of input
Parsing table
由非终结符和终结符索引的二维数组,其中非终结符和终结符包括了要在恰当的分析步骤(包括代表输入结束的$)中使用的产生式选择。
这个表被称为$M[N, T]$,这里的$N$是文法的非终结符的集合,放在表格的纵向, $T$是终结符或记号的集合(不包含ε),放在表格的横向($表示结束状态)。
空项表明一个潜在的错误
构建分析表的规则:
- 如果$A→α$是一个产生式选择,且有推导$\alpha \Rightarrow^* a \beta$ 成立,其中 $α$ 是一个记号,则将$A→α$添加到表项目$M [A, a] $中。(First规则,根据可能出现的第一个终结符填表,在输入中给出了记号α,若α可为匹配生成一个a,则希望挑选规则A→α)
- 如果$A \rightarrow \alpha$是一个产生式选择,且有推导$\alpha \Rightarrow^* ε$和 $S \,\$ \Rightarrow^* \beta A a \gamma$ 成立,其中$S$是开始符号,$a$是一个记号(或\$),则将$A→\alpha$添加到表项目$M [A, a]$中。(Follow规则,根据下一个可能出现的终结符填表,若A派生了空串(通过A→α),且如a 是一个在推导中可合法地出现在A之后的记号,则要挑选A→α以使A消失)
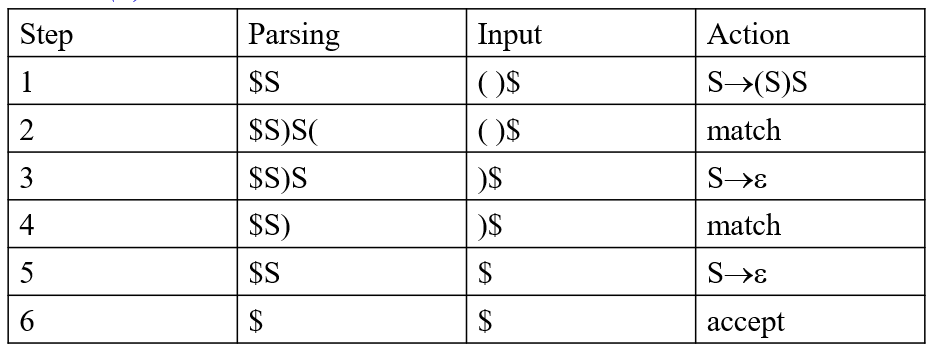
以 S -> (S)S|ε 为例,分析过程如下表所示:(Parsing表示分析栈中内容,Input表示输入内容)
Parsing Table

A parsing algorithm using the LL(1) parsing table:
1 | push the start symbol onto the top the parsing stack; |
First and Follow Sets
First sets
某文法符号展开后可能出现在第一个位置的终结符的集合
令X为一个文法符号(一个终结符或非终结符)或ε,则集合First (X) 由终结符组成,此外可能还有ε。定义如下:
若X是终结符或ε,则First(X) = {X}。
若X是非终结符,则对于每个产生式 X→X1 X2 … Xn ,First (X)都包含了First(X1) - {ε}。
若对于某个 i < n,所有的集合First(X1), … , First(Xi) 都包括了ε,则First(X) 也包括了First(Xi + 1) - {ε}。
若所有集合First(X1), …, First(Xn)包括了ε,则First(X)也包括ε。
1 | for all non-terminal A do First(A):={ }; |
Definition:
A non-terminal A is nullable if there exists a derivation A⇒∗ε
Theorem:
A non-terminal A is nullable if and only if First(A) contains ε.
Follow sets
可能出现在某文法符号后一个位置的终结符的集合
给出一个非终结符A,那么集合Follow(A)则是由终结符组成,此外可能还有$。定义如下:
若A是开始符号,则 $ 就在Follow(A)中。
若存在产生式B → αAγ,则First(γ) - {ε}在Follow(A)中。
若存在产生式B → αAγ,且ε在First(γ)中,则Follow(A)包括Follow(B)。
注意:ε永远不可能是Follow集合的元素,且Follow集合仅针对非终结符进行定义
1 | follow(start-symbol):={$}; |
Constructing LL(1) parsing table
为每个非终结符A和产生式 A→α 重复以下两个步骤:
- 对于First(α)中的每个记号a,都将A→α添加到项目M[A, a]中。
- 若ε在First(α)中,则对于Follow(A) 的每个元素a(记号或是$),都将A→α添加到M[A, a]中。
LL(1)文法的判定
A grammar in BNF is LL(1) if the following conditions are satisfied.
- For every production $A→α_1|α_2|…|α_n$, $First(α_i)∩First(α_j)$ is empty for all i and j, $1≤i,j≤n,i≠j$
- For every non-terminal A such that First(A) contains ε, First(A) ∩ Follow(A) is empty.
Error Recovery
to be continued…