Overview
自底向上的分析程序使用了显式栈来完成分析,分析栈包括记号和非终结符
分析能力:LR(0) > LALR(1) > SLR(1) > LR(0)
Right-most derivation
Start with the tokens, end with the start symbol (backward)
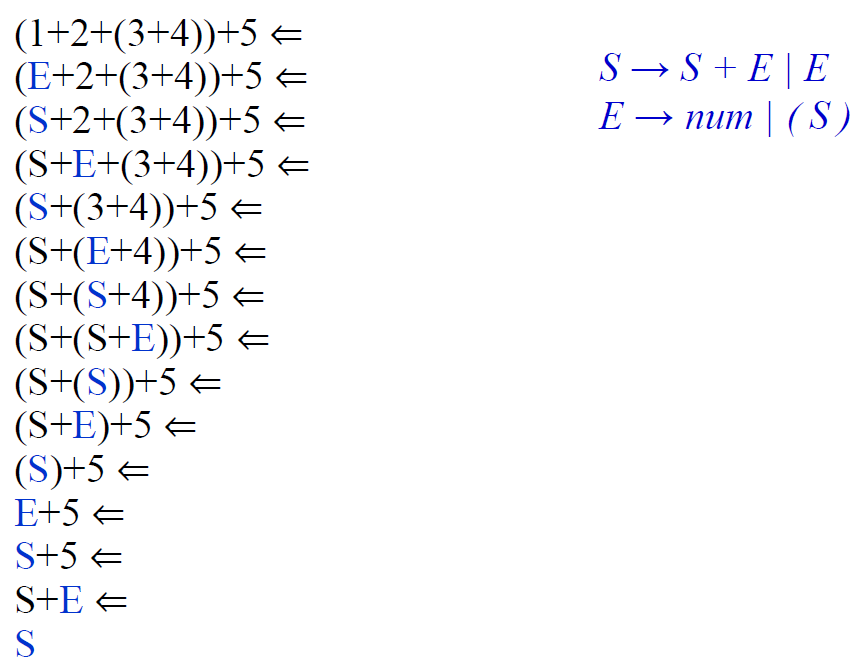
Actions
Shift: shift a terminal from the front of the input to the top of the stack.
Reduce: reduce a string α at the top of the stack to a nonterminal A, given the BNF choice A→α
自底向上的分析程序的另一个特征是:出于技术原因,总是将文法与一个新的开始符号一同扩充。若S是开始符号,那么就将新的开始符号S’增加到文法中,同时还添加一个单元产生式到前面的开始符号中:S’ → S
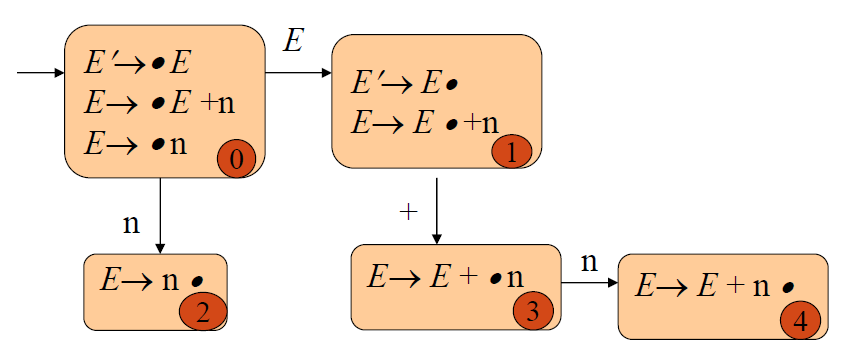
E’ → E
E → E + n | n

Right Sentential Form
Each of the intermediate strings of terminals and non-terminals in such a derivation is called a right sentential form.
Each such sentential form is split between the parsing stack and the input during a shift-reduce parse.
Viable Prefixes
The sequence of symbols on the parsing stack is called a viable prefix of the right sentential form.
E, E+ ,and E+n are all viable prefixes of the right sentential form E+n.
The right sentential form n+n has ε and n as its viable prefix.
That n+ is not a viable prefix of n+n.(因为n进栈时,栈中的n+应该已经变成了E+)
Handle
This string, together with the position in the right sentential form where it occurs, and the production used to reduce it, is called the handle of the right sentential form.
Determining the next handle in a parse is the main task of a shift-reduce parser.
Example, in step 3 of Table 5.1 a reduction by S→ε could be performed. The resulting string (SS) is not a right sentential form, thus ε is not the handle at this position in the sentential form (S .
LR(0) Items and LR(0) Parsing
Left-to-right
Rightmost
An LR(0) item of a context-free grammar: a production choice with a distinguished position in its right-hand side. 使用 · 来表示区分的位置,·前表示分析栈,·后表示输入串(If A → α , β γ = α, then A → β·γ is an LR(0) item)
E → E′
E → E+n|nLR(0) items:
E′ → ⋅E
E′ → E⋅
E → ⋅E+n
E → E⋅+n
E → E+⋅n
E → E+n⋅
E → ⋅n
E → n⋅
DFA of LR(0) items
If X is a token or a nonterminal, the item can be written as A → α·Xη

If X is a token, then this transition corresponds to a shift of X from the input to the top of the stack during a parse.
If X is a nonterminal, X will never appear as an input symbol. (such a transition will still correspond to the pushing of X onto the stack during a parse, but this can only occur during a reduction by a production X → β. )
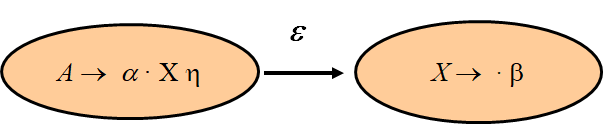
注意:根据LR(0) items生成的DFA不一定满足LR(0)文法
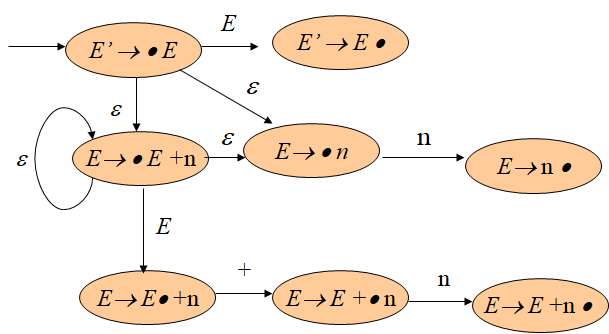
E′ → ⋅E
E′ → E⋅
E → ⋅E+n
E → E⋅+n
E → E+⋅n
E → E+n⋅
E → ⋅n
E → n⋅NFA:
DFA:
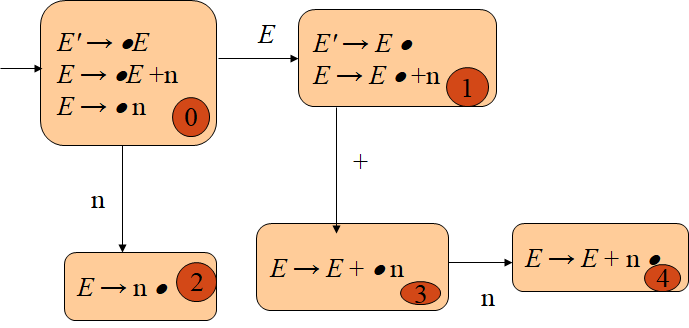
LR(0) Parsing Algorithm
分析栈中存储符号和DFA状态的编号,在向分析栈中push入符号之后要push入DFA状态的编号

Definition:
Let s be the current state (at the top of the parsing stack).Then actions are defined as follows:
If state s contains any item of the form A → α·Xβ (X is a terminal). Then the action is to shift the current input token on to the stack.
If state s contains any complete item (an item of the form A → γ·), then the action is to reduce by the rule A → γ·
A reduction by the rule S’→ S, where S’ is the start state,
Acceptance if the input is empty
Error if the input is not empty.
A grammar is said to be LR(0) grammar if the above rules are unambiguous.
A grammar is LR(0) if and only if
Each state is a shift state (a state containing only “shift” items) (不含有shift-reduce冲突)
A reduce state containing a single complete item. (不含有reduce-reduce冲突)
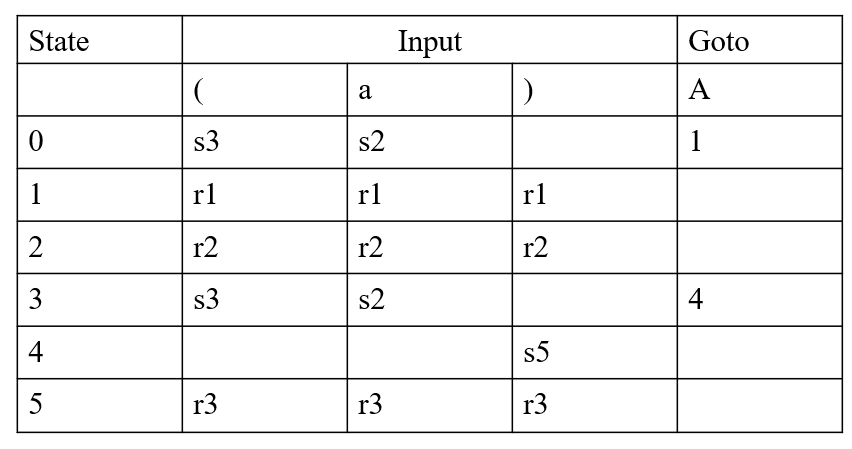
Parsing Table
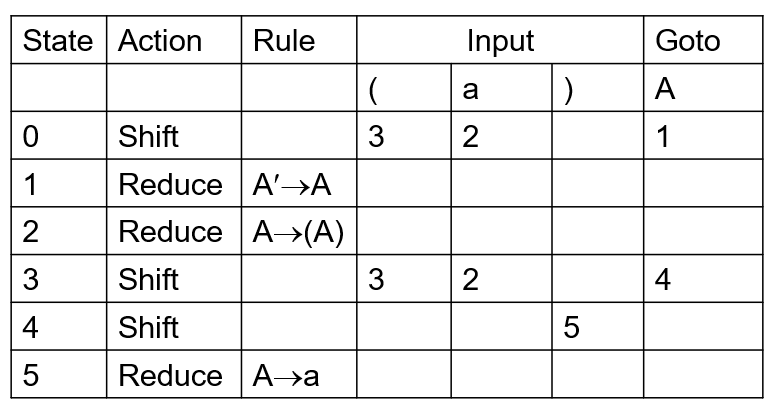
简略版:用s表示shift,r表示reduce,数字表示状态编号
SLR(1) Parsing
Definition
- If state s contains any item of form A → α·Xβ, then the action is to shift the current input token onto the stack, and the new state to be pushed on the stack is the state containing the item A→ αX·β.
- If state s contains the complete item A → γ·, and the next token in the input string is in Follow(A), then the action is to reduce by the rule A → γ.
- A reduction by the rule S’ →S, where S’ is the start state, this will happen only if the next input token is \$. (accept)
- Remove the string γ and all of its corresponding states from the parsing stack.
- Back up in the DFA to the state from which the construction of γ began.
- This state must contain an item of the form B→α·Aβ. Push A onto the stack, and push the state containing the item B → αA·β.
- If the next input token is such that neither of the above two cases applies, an error is declared.
判定
A grammar is an SLR(l) grammar: the SLR(1) parsing rules results in no ambiguity.
A grammar is SLR(1) if and only if, for any state s, the following two conditions are satisfied:
(在LR(0)前提下进行放宽)
- For any item A → α·Xβ in s with X a terminal, there is no complete item B→ γ. in s with X in Follow(B). (shift-reduce conflict)
- For any two complete items A → α·and B →β· in s, Follow(A) ∩ Follow(B) is empty. (reduce-reduce conflict)
This grammar is not LR(0), but it is SLR(1).
对于LR(0)来说,state1有shift-reduce歧义。但对于SLR(1)来说,看Follow set来判断是否有歧义。
Follow(E’) ={\$}, Follow(E) = {\$, +}
因为+不在Follow(E’)中,可以根据input来判断这个state走哪条规则,因此没有歧义(如果+在Follow(E’)中则会有歧义)
Disambiguating Rules
- (shift-reduce) Always prefer the shift over the reduce
- (reduce-reduce) Always prefer the first reduce rule (一般认为reduce-reduce conflict为error)
LR(1) Parsing
LR(1) items
将lookahead加入到item和DFA中(LR(1)项应是由L R ( 0 )项和一个先行记号组成的对)
[A → α·β, a] (A → αβ is an LR(0) item and a is a token (lookahead), 只有当下一个input是a时才进行这一步对应的操作)
The start symbol of the NFA of LR(1) items becomes the item [S’ → ·S, $].
The major difference between the LR(0) and LR(1) automata: Definition of the ε-transitions.
Definition
- Given an LR(1) item [A→α·Xγ,a], where X is any symbol (terminal or non-terminal), there is a transition
on X to the item [A→ αX·γ,a] - Given an LR(1) item [A→α·Bγ,a], where B is a nonterminal, there are ε-transitions to items [B→·β,b]
for every production B →β and for every token b in First(γa).
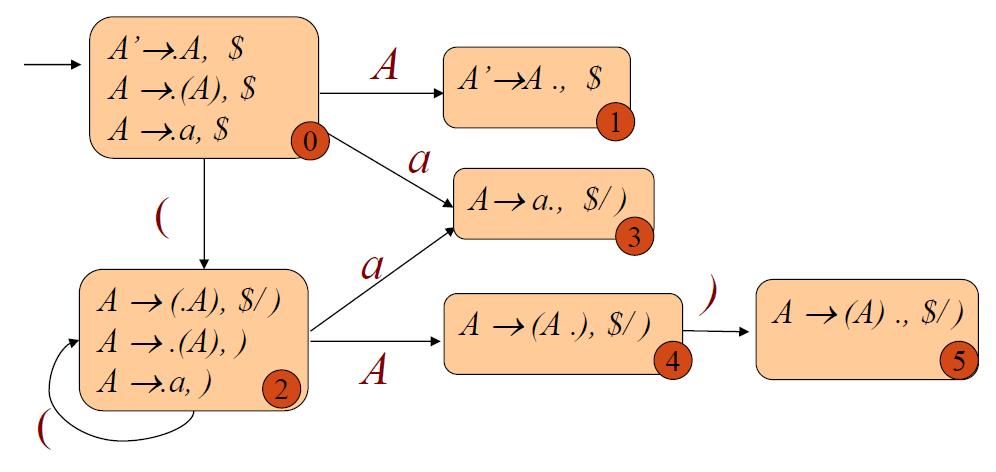
A → (A) | a
DFA:
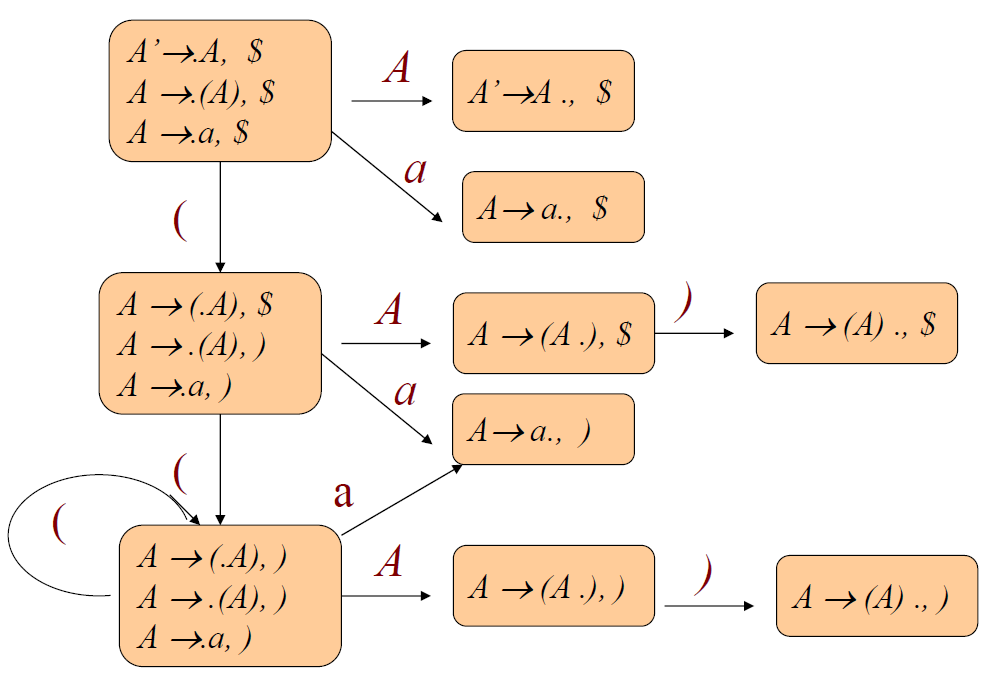
The General parsing algorithm
Let s be the current state (a the top of the parsing stack). Then actions are defined as follows:
- If state s: any LR(1) item of the form [A→α·Xβ,a], X is a terminal, and X is the next token in the input string, shift
- If state s : the complete LR(1) item [A→α·,a] , the next token in the input string is a, reduce
- If the next input token is such that neither of the above two cases applies, an error is declared.
(1) A→(A) (2) A→a
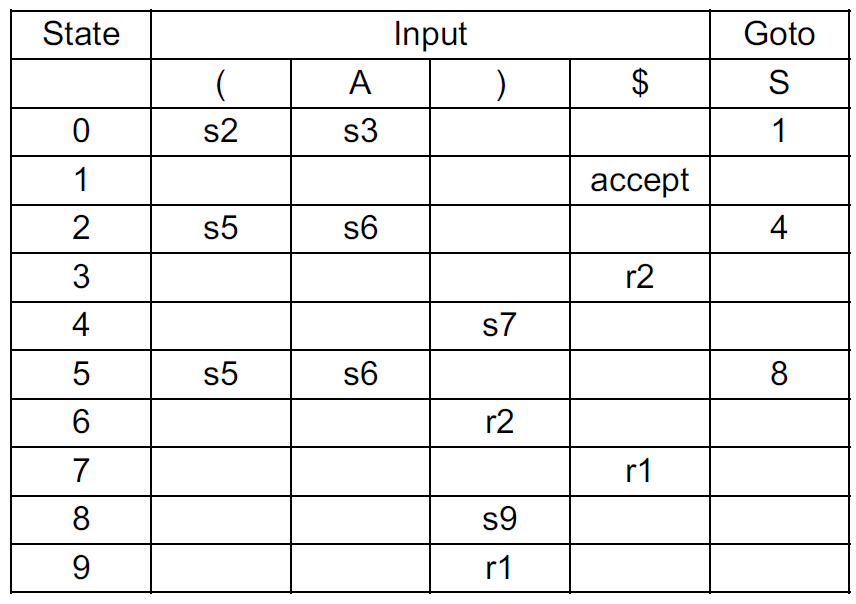
判定
A grammar is an LR(1) grammar: If the application of the above general LR( l ) parsing rules results in no ambiguity.
A grammar is LR(1) if and only if, for any state s, the following two conditions are satisfied:
For any item [A→α·Xβ,a] in s with X a terminal, there is no item in s of the form [B→γ·,X] (otherwise there is a shift-reduce conflict).
There are no two items in s of the form [A→α·, a] and [B→β·,a] (otherwise, there is a reduce-reduce conflict).
LALR(1) Parsing
在LR(1)的基础上进行合并,preserving the smaller size of the DFA of LR(0) items
- The core of a state of the DFA of LR(1) items is a state of the DFA of LR(0) items
- Given two states s1 and s2 of the DFA of LR(l) items that have the same core, suppose there is a transition on the symbol X from s1 to a state t1. Then there is also a transition on X from state s2 to a state t2, and the states t1 and t2 have the same core.
(1) A→(A) (2) A→a
A grammar is an LALR(l) grammar if no parsing conflicts arise in the LALR( l) parsing algorithm.
If a grammar is LR(l), then the LALR(l) parsing table cannot have any shift-reduce conflicts, there may be reduce-reduce conflicts.
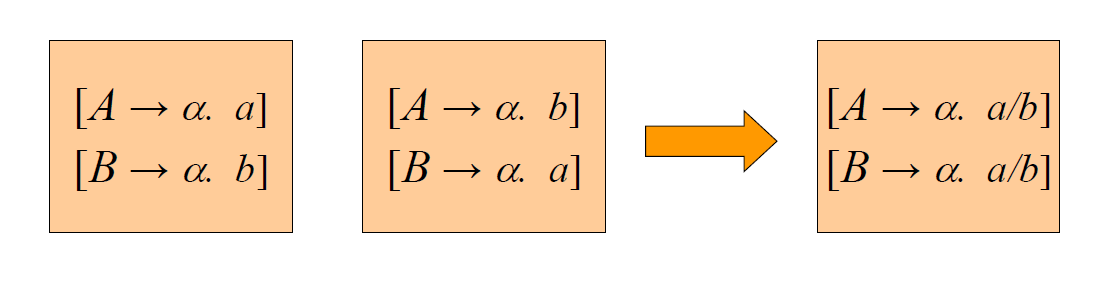
If a grammar is SLR(l), then it certainly is LALR(l)
LALR(1) parsers often do as well as general LR(1) parsers in removing typical conflicts that occur in SLR(l) parsing.
Error Recovery
A bottom-up parser will detect an error when a blank (or error) entry is detected in the parsing table.
Errors should be detected as soon as possible.
This goal conflicts with an equally important one: reducing the size of the parsing table.
An LR(1) parser can, for example, detect errors earlier than an LALR(1) or SLR(1) parser, and these latter can detect errors earlier than an LR(0) parser.
A good error recovery in bottom-up parsers: removing symbol from either the parsing stack or the input or both.
There are three possible alternative actions:
Pop a state from the stack.
Successively pop tokens from the input until a token is seen for which we can restart the parse.
- Push a new state onto the stack.
When an error occurs is as follows:
Pop states from the parsing stack until a state is found with nonempty Goto entries.
If there is a legal action on the current input token from one of the Goto states, push that state onto the stack and restart the parse.
- If there is no legal action on the current input token from one of the Goto states, advance the input.
There are several possible solutions (infinite loop)
- Insist on a shift action from a Goto state in step 2. (too restrictive )
- If the next legal move is a reduction, to set a flag that causes the parser to keep track of the sequence of states during the following reductions
- If the same state recurs, to pop stack states until the original state is removed.