引言
格式塔法则
Law of Proximity 接近性原则
物体之间的相对距离会影响我们感知它是否以及如何组织在一起。互相靠近(相对于其它物体)的物体看起来属于一组,而那些距离较远的则自动划为组外。

Law of Similarity 相似性原则
如果其它因素相同,那么相似的物体看起来归属于一组(强调内容)

Law of Common Fate 共方向原则
一起运动的物体被感知为属于一组或者是彼此相关的。如果物理沿着相似的光滑路径或具有相似的排列模式,人眼会将它们识别成一类物体。
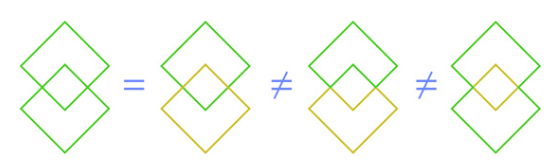
Law of Symmetry 对称性原则
人的意识倾向于将物体识别为沿某点或某轴对称的形状。
Law of Continuity 连续性原则
视觉倾向于感知连续的形式而不是离散的碎片

Law of Closure 封闭性原则
视觉系统自动尝试将敞开的图形关闭起来,从而将其感知为完整的物体而不是分散的碎片。简单理解,当图形是一个残缺图形,但主体有一种使其闭合的倾向,即主体能自行填补缺口而把其知觉为一个整体。

Marr视觉表示框架的三个阶段
Primal Sketch
将输入的原始图像进行处理,抽取图像中诸如角点、边缘、纹理、线条、边界等基本特征,这些特征的集合称为基元图
2.5D Sketch
指在以观测者为中心的坐标系中由输入图像和基元图恢复场景可见部分的深度、法线方向、轮廓等,这些信息包含了深度信息,但不是真正的物体三维表示,因此,称为二维半图
3D Model
在以物体为中心的坐标系中,由输入图像、基元图、二维半图来恢复、表示和识别三维物体
二值图像
几何特性
尺寸和位置
面积(零阶矩)
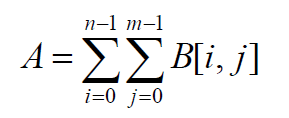
区域中心(一阶矩)
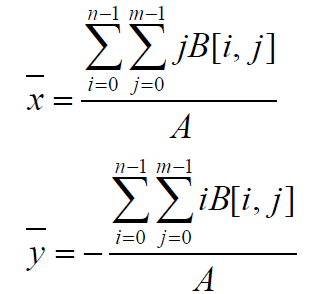
方向
方向
某些形状(如圆)是没有方向的。假定物体是长形的,长轴方向为物体的方向
求方向 –> 最小化问题
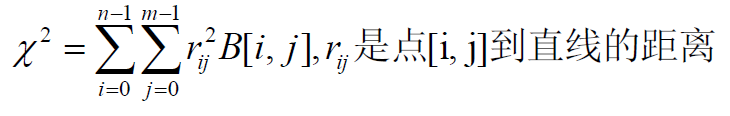
最小二乘法
伸长率
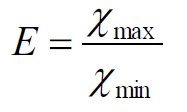
密集度

形态比
区域的最小外接矩形的长与宽之比
欧拉数(亏格数,genus)
连通分量数减去洞数:$E=C-H$,平稳,旋转和比例不变
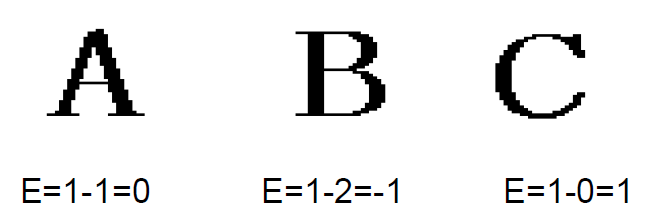
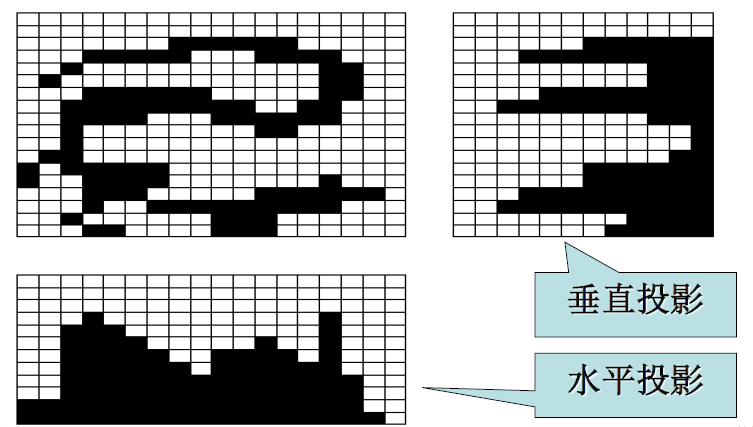
投影计算
给定一条直线,用垂直该直线的一簇等间距直线将一幅二值图像分割成若干条,每一条内象素值为 1 的象素的数量
水平/垂直
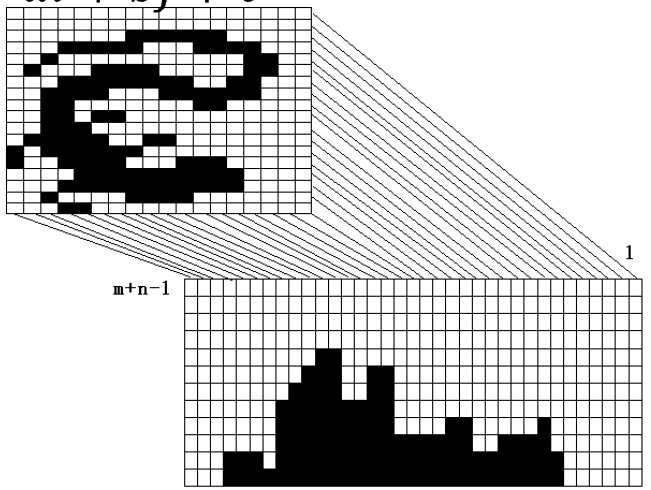
对角线
图像为$n \times m$,共对应$m+n-1$条对角线,像素点$(i,j), \; i \in [0,n-1],j\in [0,m-1]$对应的位置是$d=i-j+m $(右上对应1,左下对应$m+n-1$)
连通区域(四连通)
连通分量编辑算法
- 递归
- 扫描图像,找到没有标记的一个前景点(即像素值为 1 ),分配标记 L
- 递归分配标记 L 给该点的邻点
- 如果不存在没标记的点,则停止
- 返回第1步
- 序贯(重要)
- 从左至右、从上到下扫描图像
- 如果象素点值为 1 ,则(分 4 种情况)
- 如果上面点和左面点有且仅有一个标记,则复制这一标记
- 如果两点有相同标记,复制这一标记
- 如果两点有不同标记,则复制上点的标记且将两个标记输入等价表中作为等价标记
- 否则(两点都无标记)给这一个象素点分配一新的标记并将这一标记输入等价表
- 如果需要考虑更多点,则返回 2
- 在等价表的每一等价集中找到最低的标记
- 扫描图像,用等价表中的最低标记取代每一标记
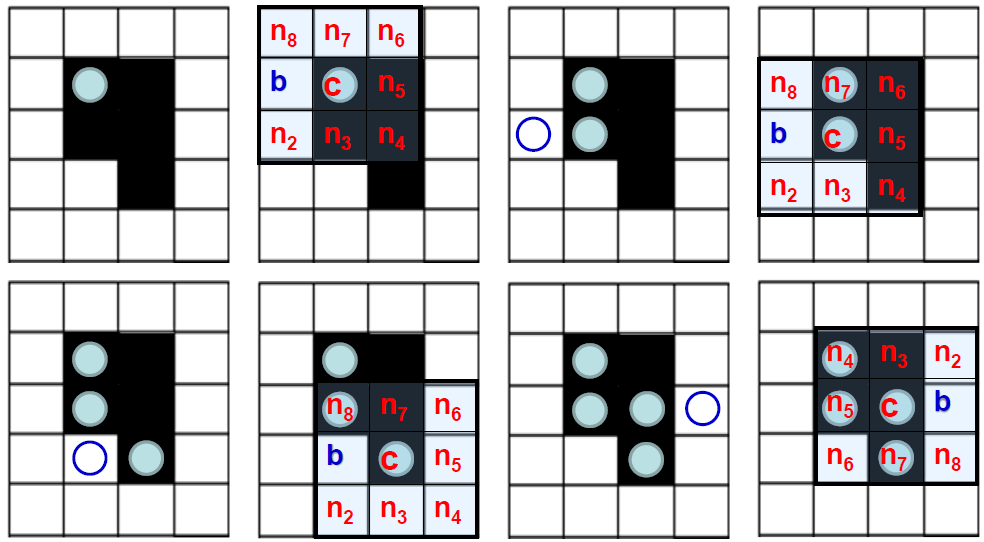
区域边界跟踪算法
c:当前点(在边界上)
b:当前点的领域点(不在边界上)
S:当前连通区域
扫描图像,求区域S的起始点(左->右,上->下):$s(k)=(x(k),y(k)),\;k=0$
用c表示当前边界上被跟踪的像素点,置 $c=s(k)$,记c的左邻点为 $b$, $b \notin S$
按逆时针方向记从b开始的c的八个邻点分别为 $n_1, n_2,…,n_8, \; k=k+1$
从b开始,沿逆时针方向找到一个 $n_i \in S$
置 $c=s(k)=n_i, \; b=n_{i-1}$ –> 保证了b不属于S
重复3,4,5步直至$s(k)=s(0)$
边缘
模板卷积
Origin of Edges
- 图像深度不连续处
- 图像(梯度)朝向不连续处
- 图像光照不连续处
- 纹理变化处
基于一阶的边缘检测
梯度
幅值:
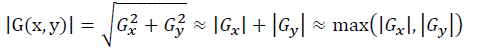
方向:$a(x,y)=arctan(G_y/G_x)$,梯度方向为函数最大变化率方向
在图像中用差分近似偏导数
$$
G_x = f[x+1,y]-f[x,y] \\
G_y=f[x,y]-f[x,y+1]
$$Roberts交叉算子
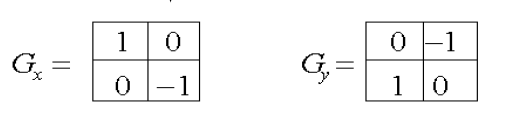
Sobel算子
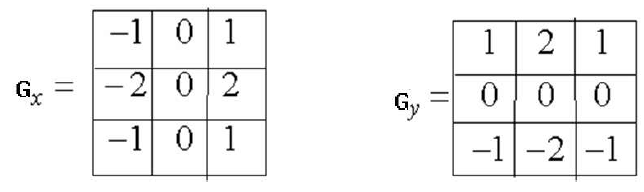
Prewitt算子(运算较快)
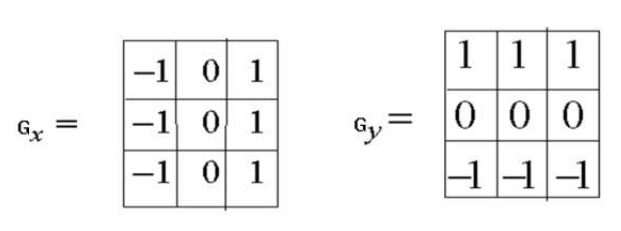
均值差分(一定邻域内灰度平均值之差)
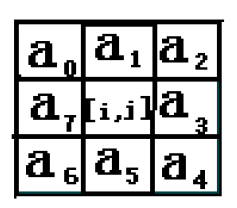
$$
G_x = (a_2+ca_3+a_4)-(a_o+ca_7+a_6) \\
G_y = (a_0+ca_1+a_2)-(a_6+ca_5+a_4)
$$
C=1: Prewitt算子C=2: Sobel算子
C=3: Sethi算子
基于二阶的边缘检测
Laplacian算子
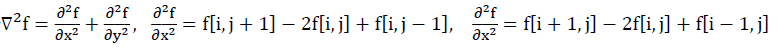
LoG算子(Laplacian of Gaussian)
高斯滤波+拉普拉斯边缘检测
基本特征:
- 平滑滤波器是高斯滤波器
- 采用拉普拉斯算子计算二阶导数
- 边缘检测判据是二阶导数零交叉点并对应一阶导数的较大峰值
- 使用线性内插方法在子像素分辨率水平上估计边缘的位置
LoG算子 =
对高斯模板求拉式算子的结果
两种等效计算方法
- 图像与高斯函数卷积,再求卷积的拉普拉斯微分
- 求高斯函数的拉普拉斯微分,再与图像卷积
Canny边缘检测(重要)
高斯滤波器平滑图像
Canny Edge 检测算法的第一个步骤是使用高斯滤波器进行滤波平滑操作,此步骤的目的是对原始图片进行模糊处理,减少原始图片的噪声,使得边缘信息更为明确。高斯滤波器是对连续高斯函数的离散近似,对高斯曲面进行离散采样和归一化得出。通过将原始图像与高斯滤波器进行卷积可以对图像实现高斯滤波平滑。
二维高斯函数如下所示:
$$
H(x,y)=e^{-\frac{x^2+y^2}{2\sigma^2}}
$$
对高斯函数进行离散化操作之后,得到 $(2k+1)\times(2k+1)$ 滤波器的计算公式如下:
$$
H[i,j] = \frac{1}{2\pi\sigma^2}e^{-\frac{(i-k-1)^2+(j-k-1)^2}{2\sigma^2}}
$$
一阶偏导有限差分计算梯度
边缘检测的一种方式是,用一阶偏导有限差分计算梯度幅值和方向检测边缘。在图像的边缘处会出现强度快速变化,因此可以通过计算图像的梯度,找出其中幅值来识别图像的边缘。由于图片信息是离散的,可以通过在单位像素点上图片强度的变化率对梯度进行离散近似。
对梯度进行离散近似之后的计算公式如下,分别计算x方向和y方向上的梯度:
$$
\frac{\partial f}{\partial x} =(\frac{f(x_{n+1},y_n)-f(x_n,y_n)}{\Delta x}+\frac{f(x_{n+1},y_{n+1})-f(x_n,y_{n+1})}{\Delta x})/2
$$
$$
\frac{\partial f}{\partial y} =(\frac{f(x_n,y_{n+1})-f(x_n,y_n)}{\Delta y}+\frac{f(x_{n+1},y_{n+1})-f(x_{n+1},y_n)}{\Delta y})/2
$$
计算梯度幅值的公式为:
$$
M=\sqrt{\frac{\partial f}{\partial x }^2 + \frac{\partial f}{\partial y} ^2}
$$
梯度方向,即函数最大变化率方模拟, 向:
$$
\theta = arctan^{-1}(\frac{\partial f}{\partial y}/\frac{\partial f}{\partial x})
$$
另一种方式是使用sobel、prewitt等算子进行卷积计算。
简化的非极大抑制(NMS)
去除幅值局部变化中非极大的点,使边缘变细。
实现方向角的离散化,即将当前坐标点的梯度方向($\theta$)根据所在的区域离散化为0, 45, 90, 135四个值。如图所示:

在离散后的梯度方向上找到幅值最大的点保留,其余点置零。
双阈值检测与边缘连接
设定两个边缘阈值TL和TH,梯度大于TH的被认为是真边缘,保留;低于TL的被认为非边缘,丢弃;介于两者之间的则根据连通性(八连通)进行判断,若其与真边缘联通,则认为是边缘,否则丢弃。
局部特征
Harris corner detector
Basic Idea
角点检测的基本思想是,使用一个固定窗口在图像上进行任意方向上的滑动,比较滑动前与滑动后两种情况,窗口中的像素灰度变化程度,如果存在任意方向上的滑动,都有着较大灰度变化,那么我们可以认为该窗口中存在角点。
当窗口发生[u,v]移动时,那么滑动前与滑动后对应的窗口中的像素点灰度变化描述如下:
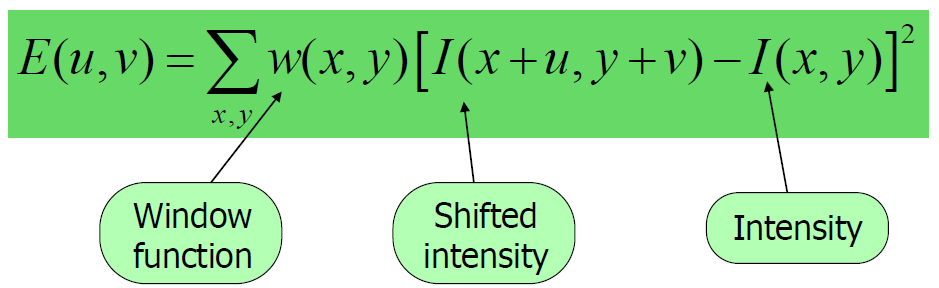
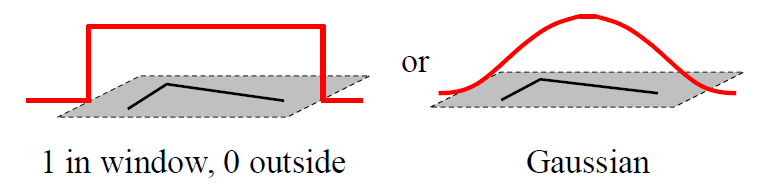
其中$[u,v]$是窗口的偏移量,$(x,y)$是窗口内所对应的像素坐标位置,窗口有多大,就有多少个位置。$w(x,y)$是窗口函数,有以下两种表示方法,最简单情形就是窗口内的所有像素所对应的w权重系数均为1。但有时候,我们会将$w(x,y)$函数设定为以窗口中心为原点的二元正态分布或高斯分布。如图所示:
根据上述表达式,当窗口处在平坦区域上滑动,可以想象的到,灰度不会发生变化,那么E(u,v) = 0;如果窗口处在比纹理比较丰富的区域上滑动,那么灰度变化会很大。算法最终思想就是计算灰度发生较大变化时所对应的位置,当然这个较大是指针任意方向上的滑动,并非单指某个方向。
我们对$E(w,v)$表达式进行泰勒展开,结果如下:
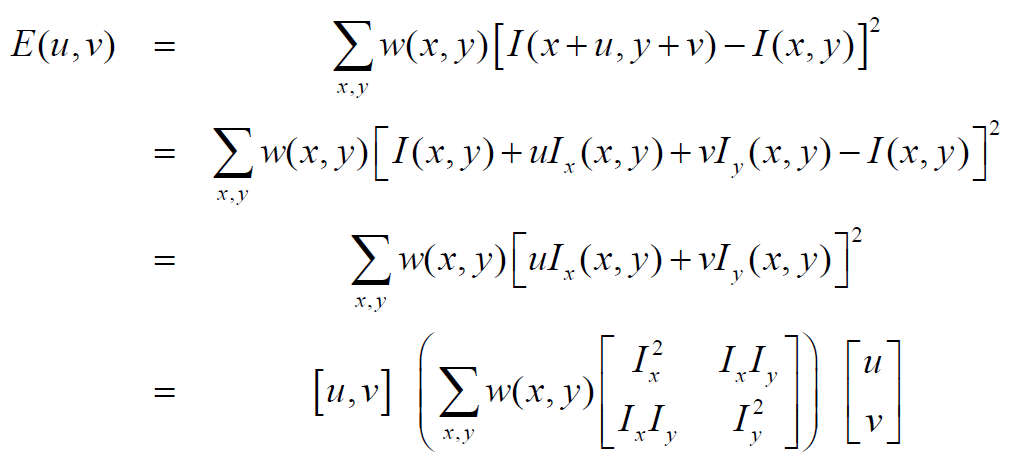
可以将$E(u,v)$表达式更新为:
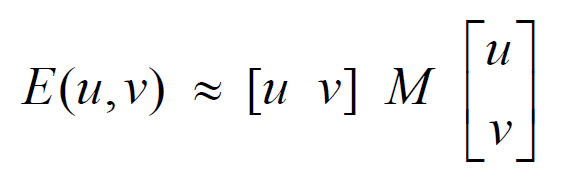
其中
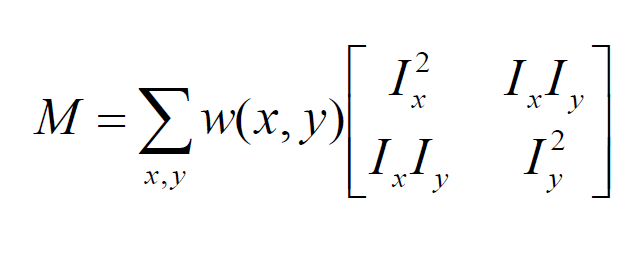
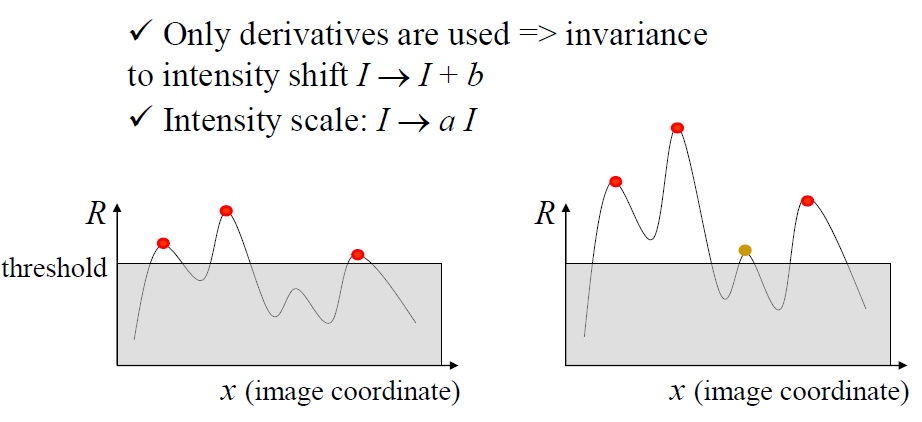
求解M的两个特征值$\lambda_1$和$\lambda_2$,可以根据两个特征值直接的关系得出对应像素点的位置信息(边缘or角点or平坦区域)
corner:在水平、竖直两个方向上变化均较大的点,即Ix、Iy都较大;
edge :仅在水平、或者仅在竖直方向有较大的点,即Ix和Iy只有其一较大 ;
flat : 在水平、竖直方向的变化量均较小的点,即Ix、Iy都较小;
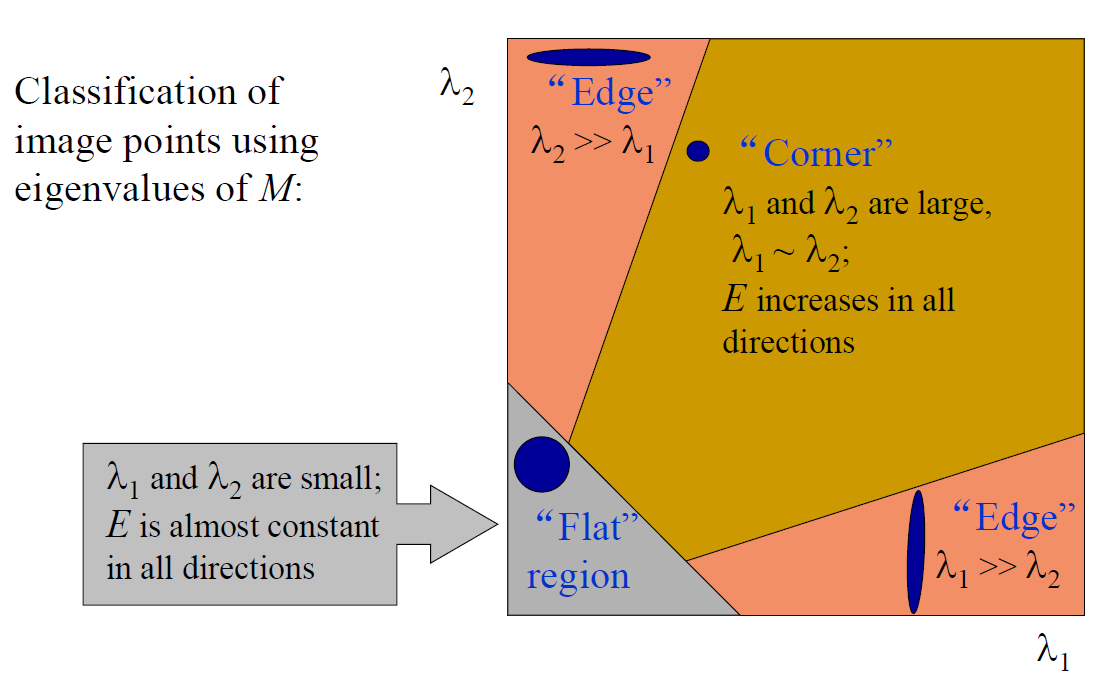
可以定义角点响应函数R来表示:

其中k是介于0.04-0.06间的常数。
针对三种不同区域的点,R的取值情况如下:
corner:R为大数值整数
edge:R为大数值负数
flat:绝对值R是小数值
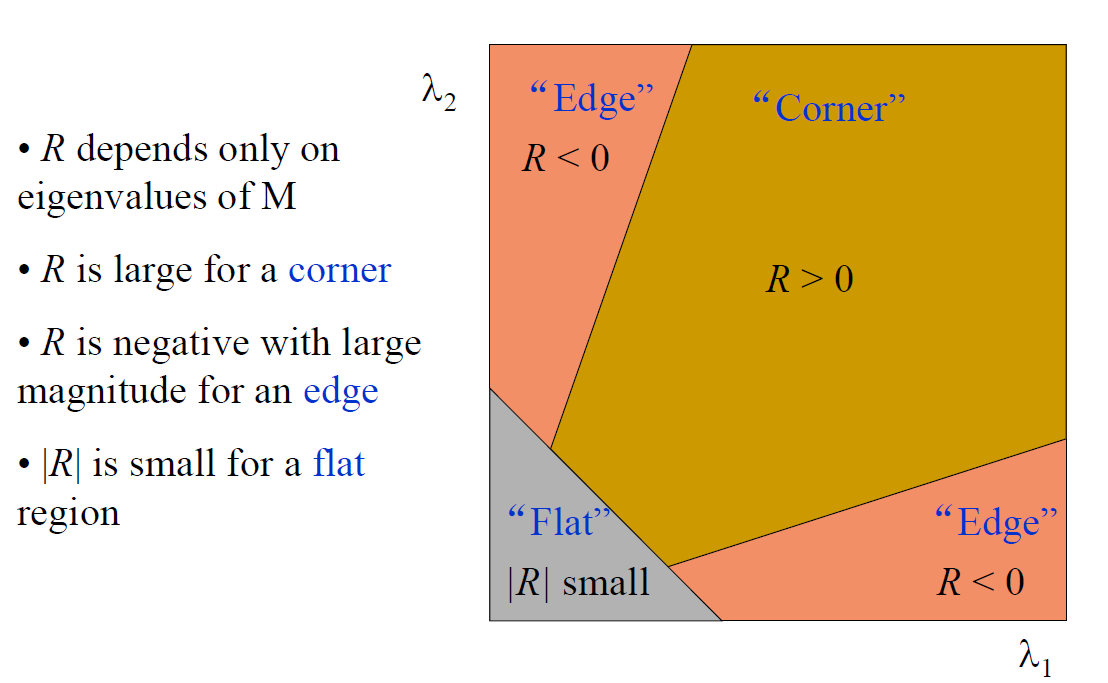
旋转不变性
灰度不变性
尺度不变性
不满足尺度不变性
SIFT
- 尺度空间极值检测:搜索所有尺度上的图像位置。通过高斯差分函数来识别潜在的对于尺度和旋转不变的兴趣点。
- 关键点定位:在每个候选的位置上,通过一个拟合精细的模型来确定位置和尺度。关键点的选择依据于它们的稳定程度。
- 方向确定:基于图像局部的梯度方向,分配给每个关键点位置一个或多个方向。所有后面的对图像数据的操作都相对于关键点的方向、尺度和位置进行变换,从而提供对于这些变换的不变性。
- 关键点描述:在每个关键点周围的邻域内,在选定的尺度上测量图像局部的梯度。这些梯度被变换成一种表示,这种表示允许比较大的局部形状的变形和光照变化
Basic idea
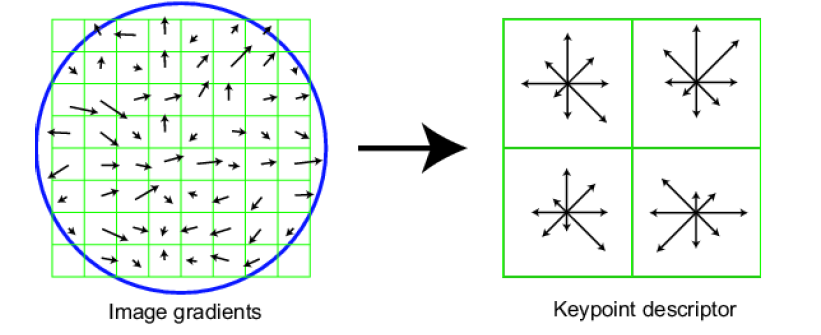
- 用16*16的窗口放在特征点附近 + 将16*16分成16个4*4的窗口
- 计算窗口中每个像素的边的方向(梯度角减去90°)
- 丢掉方向能量小的边(使用阈值)
- 用直方图描述结果 + 将每个小窗口中的所有的方向离散成8个方向,一共16*8=128个
Full version
- Divide the 16 x 16 window into a 4 x 4 grid of cells ( 2 x 2 case shown below)
- Compute an orientation histogram for each cell
- 16 cells * 8 orientations = 128 dimensional descriptor
使用梯度的原因、好处
梯度信息可以表示边缘信息,并且在光照变化时有抵抗能力
尺度不变&旋转不变
https://www.jianshu.com/p/c0379c931e74
https://bbs.csdn.net/topics/390457105
曲线
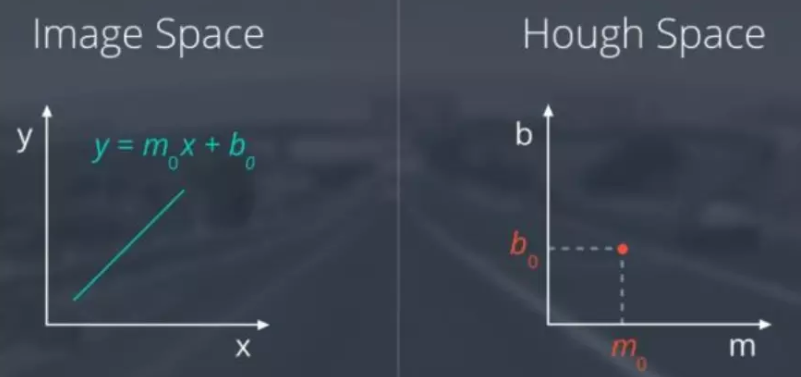
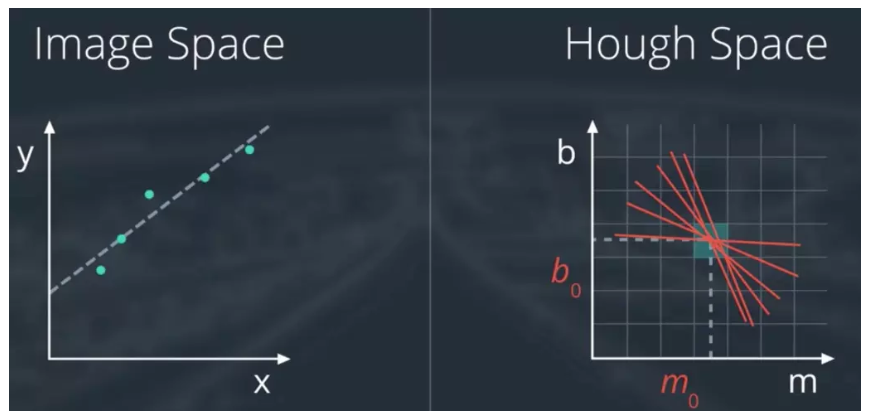
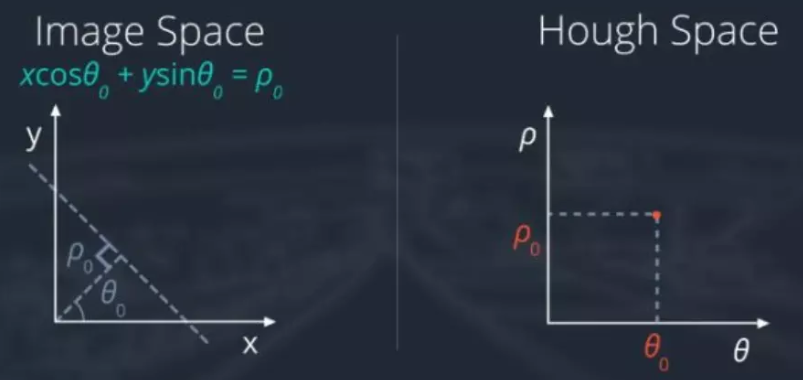
Hough变换(重要)
Hough 变换是基于投票(Voting)原理的参数估计方法,是一种重要的形状检测技术。
基本思想
图像中每一点对参数组合进行表决,赢得多数票的参数组合为胜者(结果)
主要步骤
- 适当地量化参数空间(合适的精度即可)
- 假定参数空间的每一个单元都是一个累加器,把累加器初始化为零.
- 对图像空间的每一点,在其所满足的参数方程对应的累加器上加 1
- 累加器阵列的最大值对应模型的参数.
直线检测
https://www.jianshu.com/p/ddbeb8e7d8be



圆弧检测

- 量化关于a,b的参数空间到合适精度
- 初始化所有累加器为0
- 计算图像空间中边缘点的梯度幅度 $G_{mag}(x,y)$ 和角度 $\theta (x,y)$
- 若边缘点参数坐标满足 $b=a\, tan \theta -x\, tan \theta + y$ 则该参数坐标对应的累加器加1
- 拥有最大值的累加器所在的坐标即为图像空间中的圆心之所在
- 得到圆心坐标之后,我们可以很容易反求r
人脸识别
主元分析(PCA)
主要思想
PCA (Principal Component Analysis),即主成分分析方法,是一种使用最广泛的数据降维算法。PCA的主要思想是将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征。PCA的工作就是从原始的空间中顺序地找一组相互正交的坐标轴,新的坐标轴的选择与数据本身是密切相关的。其中,第一个新坐标轴选择是原始数据中方差最大的方向,第二个新坐标轴选取是与第一个坐标轴正交的平面中使得方差最大的,第三个轴是与第1,2个轴正交的平面中方差最大的。依次类推,可以得到n个这样的坐标轴。通过这种方式获得的新的坐标轴,我们发现,大部分方差都包含在前面k个坐标轴中,后面的坐标轴所含的方差几乎为0。于是,我们可以忽略余下的坐标轴,只保留前面k个含有绝大部分方差的坐标轴。事实上,这相当于只保留包含绝大部分方差的维度特征,而忽略包含方差几乎为0的特征维度,实现对数据特征的降维处理。
适用的数据
适用于PCA的数据也是统计意义上有强相关性的数据,维度过高但高维信息量低,相关度高的数据(多元高斯分布)
优化目标函数推导
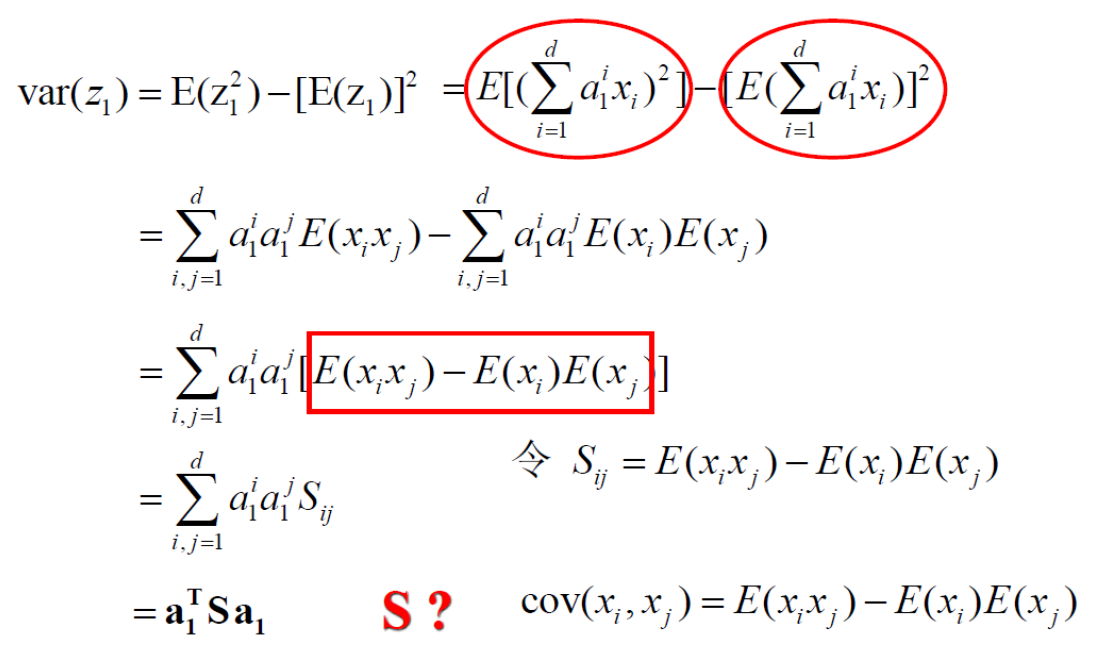
Eigenface 人脸识别算法
基本步骤
- 获得人脸图像的训练集,通常为整个人脸数据库
- 对所有人脸图像作归一化处理
- 通过 PCA 计算获得一组特征向量(特征脸)。通常一百个特征向量就足够
- 将每幅人脸图像都投影到由该组特征脸张成的子空间中,得到在该子空间坐标
- 对输入的一幅待测图像,归一化后,将其映射到特征脸子空间中。然后用某种距离度量来描述两幅人脸图像的相似性,如欧氏距离
重构原理
识别:将两张图像都投影到人脸空间,比较投影向量的欧氏距离。
重构:将图像投影到人脸空间,通过左乘特征人脸空间矩阵恢复
人脸投影到特征人脸空间中,保留了主要特征的信息,所以可以恢复人脸本来的样子

图像频域与图像分解
图像的傅里叶变换
基本含义
任何连续周期信号都可以表示成(或者无限逼近)一系列正弦信号的叠加,将时间域上的信号转变为频率域上的信号。在一维领域,信号是一维正弦波的叠加,那么想象一下,在二维领域,实际上是无数二维平面波的叠加。
Fourier transform stores the magnitude and phase at each frequency
- Magnitude encodes how much signal there is at a particular requency
- Phase encodes spatial information (indirectly)
- For mathematical convenience, this is often notated in terms of real and complex numbers
基图像
可以将任一4*4像素块表示为16个基图像的加权和,权值即为对应位置的DCT系数

高频/低频
图像的频率是表征图像中灰度变化剧烈程度的指标,是灰度在平面空间上的梯度
图像的高频部分是像素值变化剧烈的地方,如图像的边缘和轮廓。低频部分是变化不剧烈的地方,对应大的色块。我们从近处看图像看到的是高频信息,而远处看到的是低频信息
图像分解
从图像分解角度理解傅里叶变换
傅立叶变换将图像从空间域转换到频率域,将图像的灰度分布函数变换为图像的频率分布函数
拉普拉斯图像金字塔的每一层是带通滤波
拉普拉斯金字塔是将图像下采样后再上采样得到的差值图像,通过源图像减去先缩小再放大的一系列图像构成的。下采样的时候丢失了高频信息,而相邻金字塔相减的时候丢失了低频信息,因此只有中间频段的信息保留了下来
图像拼接
RANSAC
RANSAC是“RANdom SAmple Consensus(随机抽样一致)”的缩写。它可以从一组包含“局外点”的观测数据集中,通过迭代方式估计数学模型的参数,解决3D重建中的位置确定问题,图像匹配、全景拼接
核心思想
采用迭代的方式从一组包含outliers的数据中估算数学模型的参数。核心思想是随机性和假设性,随机性是根据正确数据出现的概率去随机选取抽样数据,假设性是假设选取出的抽样数据都是正确数据。
优点
是大范围模型匹配问题的一个普遍意义上的方法,且运用简单,计算快
缺点
只能计算outliers不多的情况(投票机制可以解决outliers高的情况)
基本步骤
- 随机选择一些点作为样本
- 计算选出的样本应该使用的变换矩阵
- 把刚才没有选中的点代入建立的模型,判断有多少点符合,误差是否小于阈值
- 比较匹配数量是否为当前最优解,如果是,则更新当前最优集,并更新迭代次数
重复多次,如果迭代次数大于K(k由最优的inliers的点集计算得到),则退出,否则迭代次数+1

成功概率

图像拼接
基本步骤
- Detect key points SIFT特征提取
- Build the SIFT descriptors 建立SIFT描述子
- Match SIFT descriptors 特征点匹配(knn)
- Fitting the transformation(RANSAC计算Homography矩阵,进行变换)
- Image Blending 图像融合
物体识别
Visual Recognition
基本任务
- 图片和视频的分类
- 检测和定位物体/图片分割
- 估计语义和几何属性
- 对人类活动和事件进行分类
挑战因素
- 视角变换
- 光线变化
- 尺度变化
- 物体形变
- 物体遮挡
- 背景凌乱
- 内部类别多样
基于词袋(BoW)的物体分布
BoW(bag-of-words)
图像中的单词被定义为一个图像块的特征向量,图像的Bow模型即图像中所有图像块的特征向量得到的直方图
基本步骤
- 特征提取和表示(grid),每个特征为一个质点
- 通过对质点聚类建立字典(k 聚类),得到k个聚类中心,聚类中心就是词袋中的单词,所有聚类中心就是特征直方图的基
- 将图片用直方图的基表示出来,这样就可以得到关于图片的特征直方图。该直方图与单词的顺序没有关系,而是每个单词在图片中出现的频率
- 将新的图片获取质点,然后映射到直方图上进行聚类
深度学习
深度网络学习
end-to-end 学习
raw inputs to predictions
从输入端(输入数据)到输出端会得到一个预测结果,与真实结果相比较会得到一个误差,这个误差会在模型中的每一层传递(反向传播),每一层的表示都会根据这个误差来做调整,直到模型收敛或达到预期的效果才结束
端到端指的是直接输入原始数据,让模型自己去学习特征,最后输出结果。中间不再需要人工的参与,就像一个工厂,送进去玉米,最后出来爆米花,中间的流程我们一律不参与。
数学本质
通过不断尝试引入各种参量,最终得到允许误差范围内的解,并通过引入参量系数,最终得到最优解。不断地更新参数 W 和 b 的值从而使损失函数最小化。(给定结构,求解连接关系的权重)
常用基本方法
梯度下降法
CNN 卷积神经网络
卷积层
卷积层的作用是提取图像的各种特征,是卷积核在上一级输入层上通过逐一滑动窗口计算而得,卷积核中的每一个参数都相当于传统神经网络中的权值参数,与对应的局部像素相连接,将卷积核的各个参数与对应的局部像素值相乘之和,(通常还要再加上一个偏置参数),得到卷积层上的结果。
池化层
池化层的作用是对原始特征信号进行抽象,从而大幅度减少训练参数,另外还可以减轻模型过拟合的程度。池化/采样的方式通常有以下两种:
- Max-Pooling: 选择Pooling窗口中的最大值作为采样值;
- Mean-Pooling: 将Pooling窗口中的所有值相加取平均,以平均值作为采样值;
相关计算




BP算法
作用
误差反向传播是将输出误差以某种形式通过隐层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层的误差信号,此误差信号即作为修正单元权值的依据。这种信号正向传播与误差反向传播的各层权值调整过程周而复始的进行,权值不断调整的过程,也就是网络学习训练的过程,此过程一直进行到网络输出的误差减少到可接受的程度,或进行到预先设定的学习次数为止
使用简单的方法有效的减少了计算量
仅用于计算梯度
计算
梯度算法 vs BP算法
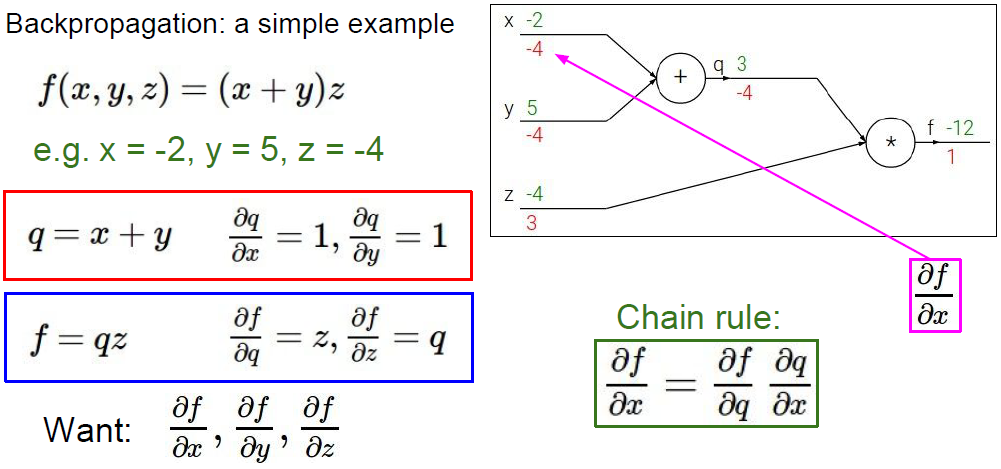
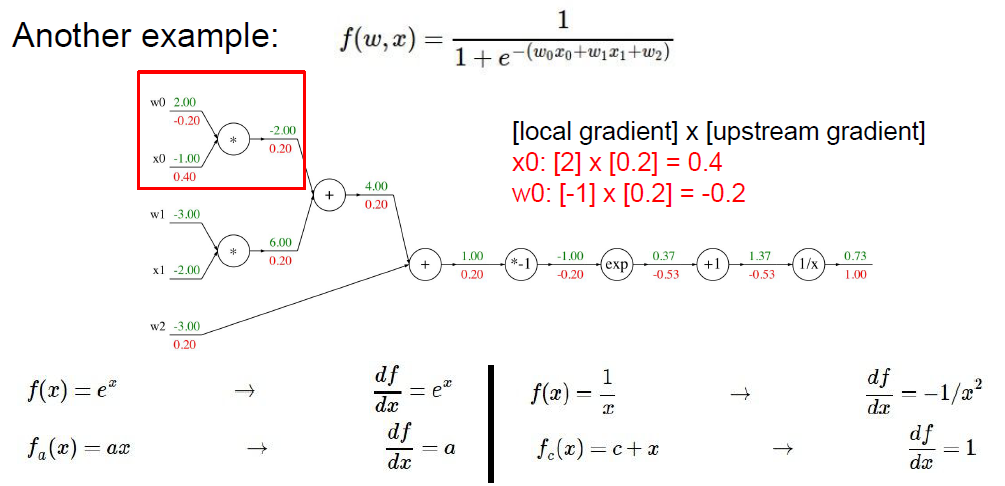
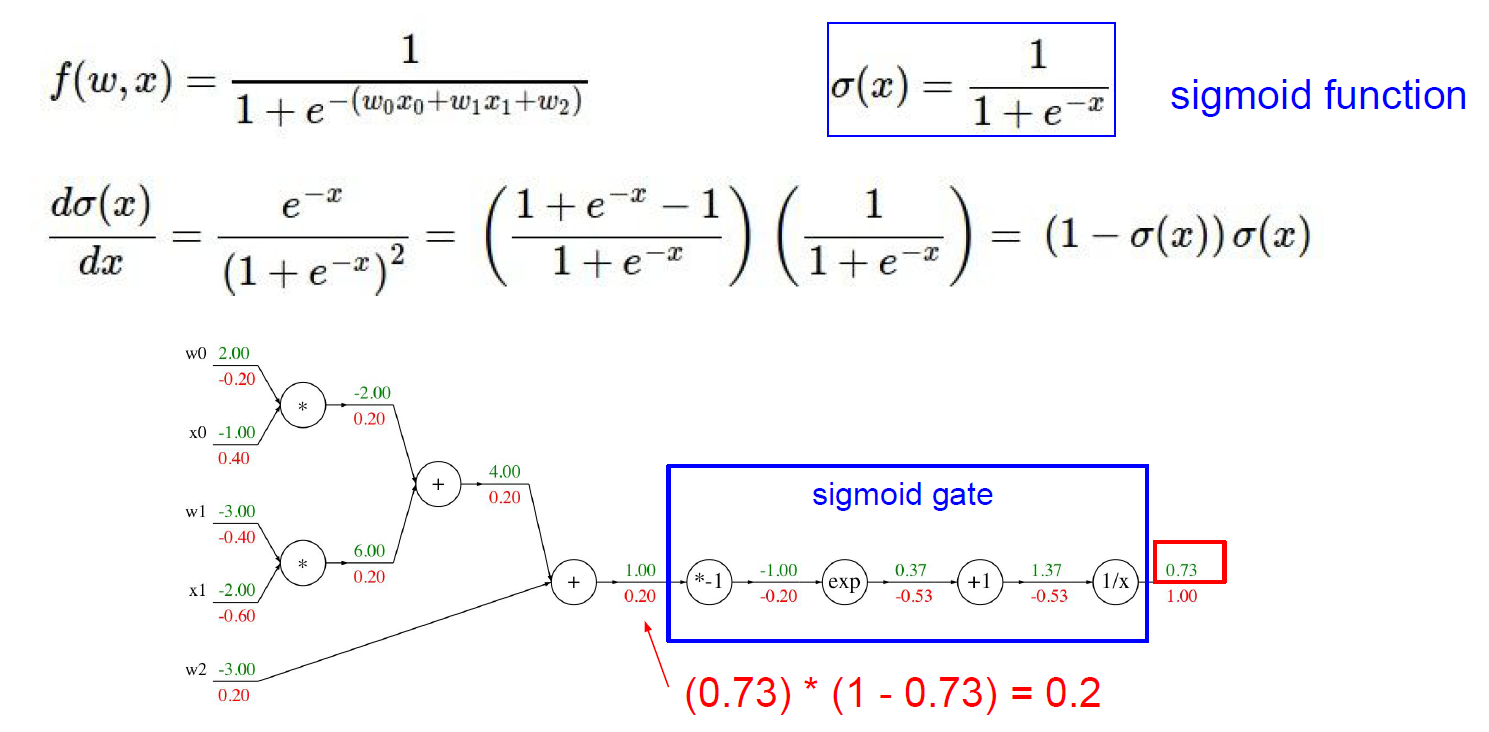
通过梯度下降算法,求取每个参数的偏导数,更新参数实现反向传播以此来让我们的模型更能准确的预测问题。
BP算法由信号的正向传播和误差的反向传播两个过程组成。
正向传播时,输入样本从输入层进入网络,经隐层逐层传递至输出层,如果输出层的实际输出与期望输出(导师信号)不同,则转至误差反向传播;如果输出层的实际输出与期望输出(导师信号)相同,结束学习算法。
反向传播时,将输出误差(期望输出与实际输出之差)按原通路反传计算,通过隐层反向,直至输入层,在反传过程中将误差分摊给各层的各个单元,获得各层各单元的误差信号,并将其作为修正各单元权值的根据。这一计算过程使用梯度下降法完成,在不停地调整各层神经元的权值和阈值后,使误差信号减小到最低限度。
光流
解决的问题
给定两张图像H和I,评估从H到I的像素运动,解决的是像素对应的问题
基本假设
- brightness constancy 亮度恒定
- spatial coherence 空间相干
- small motion 细微运动
约束公式
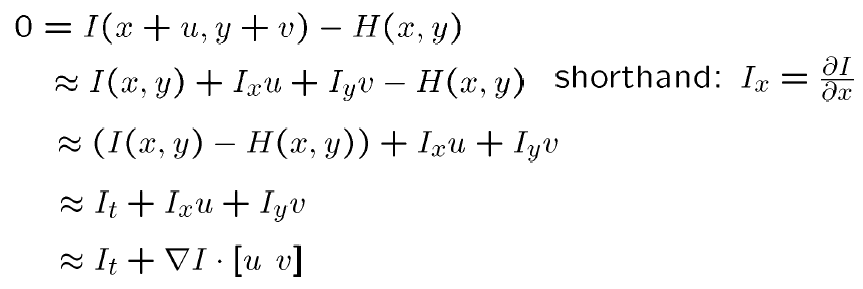
可靠位置
纹理复杂区域,梯度比较大且方向不同,求出来的特征值比较大,光流比较可靠
相机模型
理解
景深
相机镜头能够取得清晰图像的成像所测定的被摄物体前后范围距离
光圈
镜头中,用来控制光线透过镜头,进入机身内感光面光量的装置
焦距
从镜片中心到底片等成像平面的距离
视场
摄像头能够观察到的最大范围
光圈vs景深
较小的光圈对应较大的景深
但是较小的光圈限制了光线的进入,因此需要增加曝光
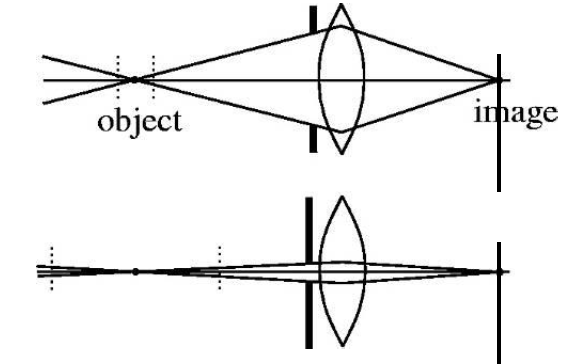
焦距vs视场
焦距越短,视场角越大,放大倍率越小,拍摄范围越大,拍摄画面中的人越小
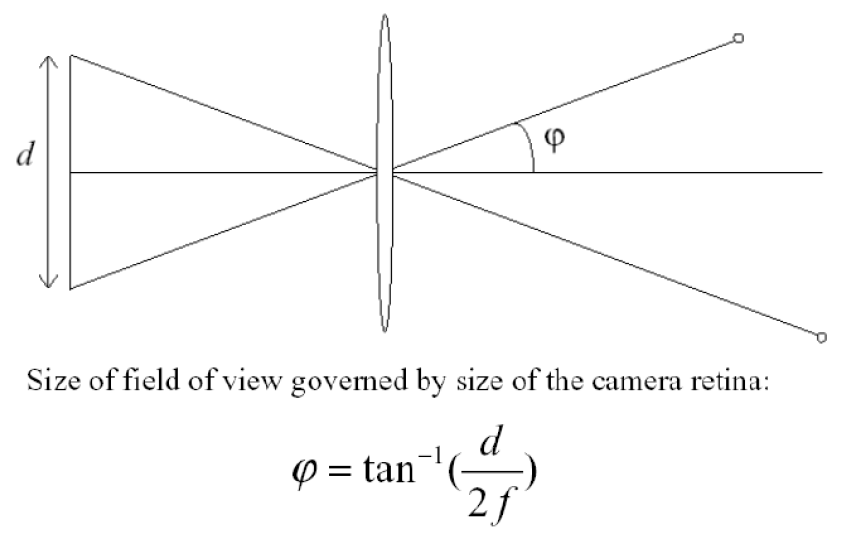
理想的针孔相机模型
基本投影公式
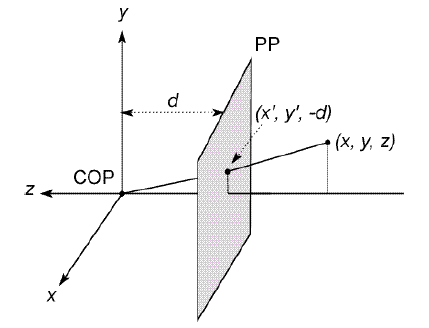

齐次坐标下的透视投影
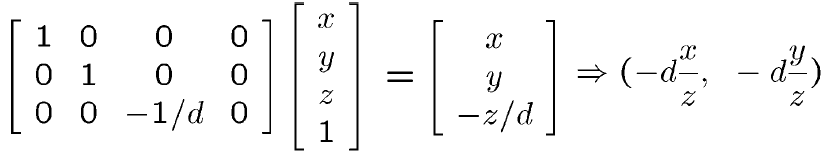
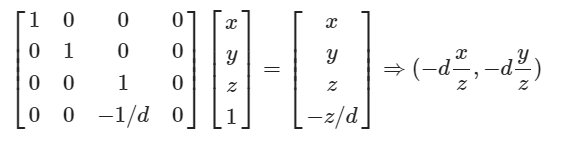
齐次坐标表示的好处
- 齐次坐标可以表示无穷远处的点
- 把各种变换都统一了起来,即把缩放,旋转,平移等变换都统一起来,都表示成一连串的矩阵相乘的形式。保证了形式上的线性一致性
- 合并矩阵运算中的乘法和加法
内参
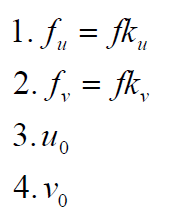
内参矩阵
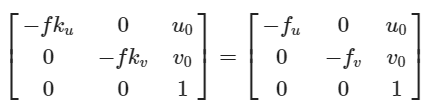
畸变
原因
径向畸变
不完美的镜头,镜片的不理想,镜头的几何形状,光圈位置
↑ 概括成透镜几何性质和孔径位置
远离透镜中心的地方比靠近中心的地方更加弯曲切向畸变
由于CMOS等感光元件摆放倾斜,没有平行于图像平面
越靠近中间,畸变越小
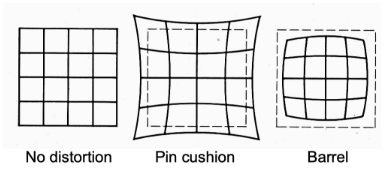
径向畸变类型
- 枕形畸变:中间向外凸起
- 桶形畸变:中间向内凹陷
外参
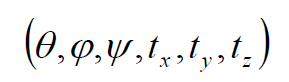
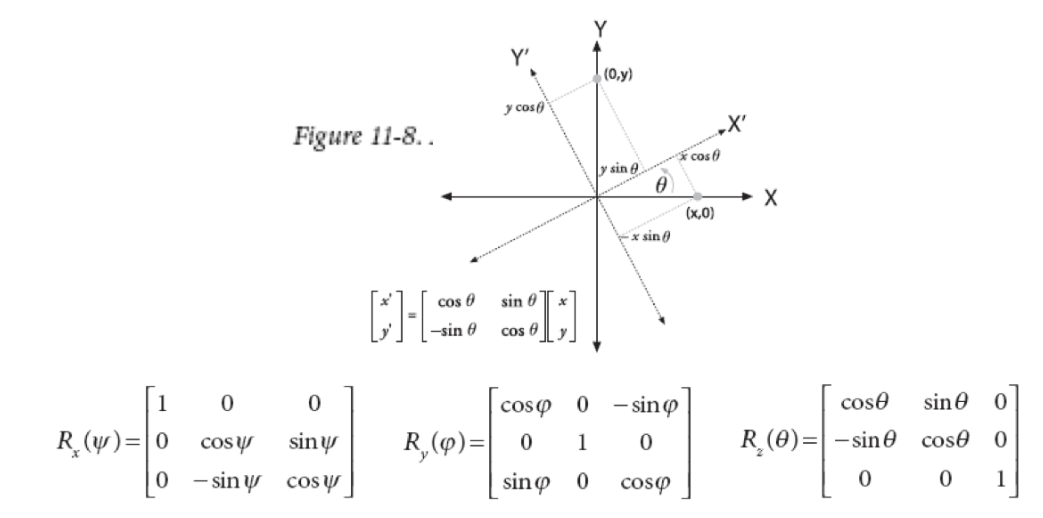
前三个指的是旋转参数,后三个指的是平移参数
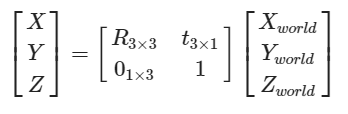
内参、外参、畸变参数在成像阶段中的角色
- 第一步是从世界坐标系转为相机坐标系,这一步是从三维点到三维点的转换,包括R,t等参数(相机外参)
- 第二步是从相机坐标系转为成像平面坐标系(像素坐标系),这一步是三维点到二维点的转换,包括K等参数(相机内参)
- 最后再用到畸变参数

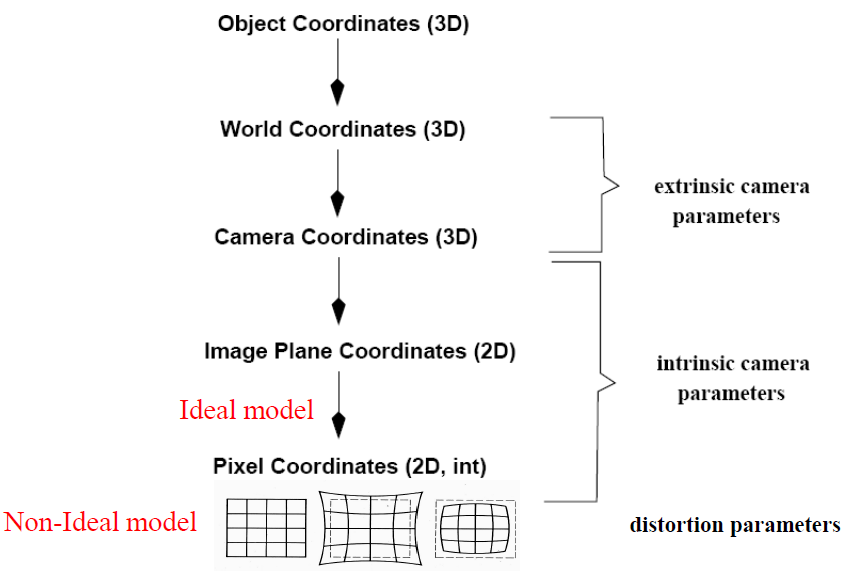
相机定标
一般的相机定标
要求解的参数
畸变参数,内参,外参
基本思想
已知:给定标定物体的N个角点,K个视角(棋盘格子两个点可以得出四个等式)
求解:Distortion coeffients , intrinsic para, extrinsic para。N个点K个视角可以列出2NK个等式,会带来6K+4个参数。每次会变的是外参,而内参和畸变参数是不变的,所以只需要2NK>6K+4即可
基于Homography的相机定标
优点
三维标定物可由单幅图像进行标定,标定精度较高,但高精密三维标定物的加工和维护较困
难。平面型标定物比三维标定物制作简单,精度易保证,可以使用于任意的摄像机模型,标
定精度高
基本过程
- 获取标定物体网格的角点在坐标系的位置
- 找到图片的角点
- 根据图像空间坐标系到世界坐标系列出等式
- 求解相机参数
自由度
9个参数,8个自由度,求解至少需要4个点,8个等式
立体视觉
三角测量基本原理
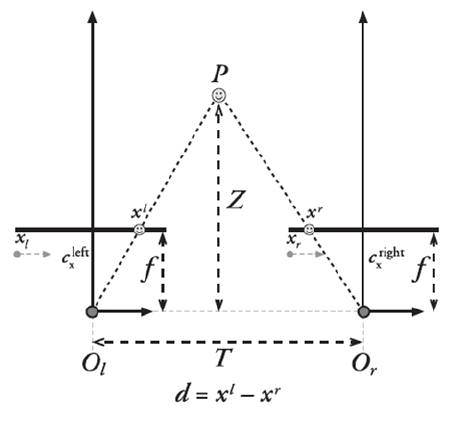
Triangulation公式
基本步骤
Undistortion
remove distortions -> undistorted images 恢复失真,消除畸变
Rectification
adjust cameras -> the two images row-aligned 矫正相机,使图像在同一个平面上Correspondence
find the same features in the two images -> disparity 在两张图中找到对应的相同特征Reprojection
triangulation -> a depth map 三角测量
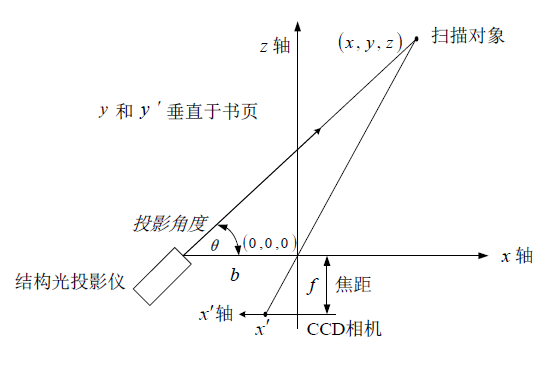
结构光三维成像
结构光三维成像系统的构成
一个结构光三维成像系统主要由三个部分组成:结构光投影仪(一台或多台),CCD相机(一台或多
台),以及深度信息重建系统
利用结构光获取三维数据的基本原理
- 观测对象坐标(x,y,z) ?
- 成像坐标(x’,y’)
- 投影角度θ.
- 投影仪与镜头的距离b
- 焦距f
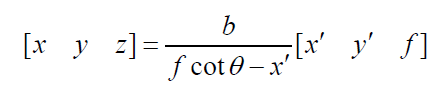
ICP问题
解决的问题
ICP(Iterative Closest Point)是根据前后两帧图像中匹配好的特征点在相机坐标系下的三维坐标,求解相机帧间运动的一种算法。
迭代最近点方法(用于多个摄像机的配准问题,即把多个扫描结果拼接在一起形成对扫描对象的完整描述)计算两组数据(两帧图像)间的旋转平移量,使之形成最佳匹配
registeration点云配准问题
基本步骤
给定两个三维点集X与Y,将Y配准到X:
- 计算Y中的每一个点在X中的对应最近点
- 求使上述对应点对的平均距离最小的刚体变换,获得刚体变换参数(平移参数和旋转参数)
- 对Y应用上一步求得的刚体变换(平移和旋转),更新Y
- 如果X与Y的对应点对平均距离大于阈值,回到1,否则停止计算
图像分割
基于k-means聚类的图像分割
基本原理
- 对相似的点进行分类,并用一个符号表示
- 迭代的将点归类到最近的聚类中心上
基本步骤
- 随机选择K个聚类中心
- 对图像上所有点,根据其与聚类中心的距离,将其划分到距离最近对应的中心的聚类簇
- 重新计算每一簇的均值来更新中心(簇内均值)
- 重复2,3步,直到no points are re-assigned
基于Mean Shift的图像分割
基本原理
假设不同簇类的数据集符合不同的概率密度分布,找到任一样本点密度增大的最快方向(最快方向的含义就是Mean Shift),样本密度高的区域对应于该分布的最大值,这些样本点最终会在局部密度最大值收敛,且收敛到相同局部最大值的点被认为是同一簇类的成员。
基本步骤
- Choose kernel and bandwidth
- For each point
- center a window on that point
- compute the mean of the data in the search window
- center the search window at the new mean location
- Repeat (b, c) until convergence
- Assign points that lead to nearby modes to the same cluster
与k-means相比的好处
- Good general-purpose segmentation
- Flexible in number and shape of regions
- Robust to outliers