已实现的功能简述及运行简要说明
功能简述
利用CNN进行手写数字识别与物体分类:
- 使用PyTorch工具实现最基本的卷积神经网络(CNN) LeNet-5以及一个物体分类的CNN
- 用MNIST手写数字数据集(0-9一共十个数字)6万样本实现对LeNet-5的训练,对MNIST的1万测试样本进行测试,获得识别率。
- 用CIFAR-10数据库实现CNN物体分类功能的训练与测试。
运行简要说明
由于本次实验使用的两个测试集都比较经典,在torchvision库中都已经做了封装,因此在本实验中选择了直接调用。运行程序后,将先将指定数据集下载到指定路径中,然后再进行训练。为了节省下载时间,也可以将下载好的数据集添加到对应路径(./data/)中直接进行训练。
MNIST.py用于训练MNIST测试集,CIFAR.py用于训练CIFAR-10测试集。
开发与运行环境
操作系统:Windows 10,64位
开发环境:Python 3.7.3
库环境:numpy 1.16.4, torch 1.1.0, torchvision 0.3.0
算法基本思路、原理
CNN
卷积神经网络(Convolutional Neural Network, CNN)是深度学习技术中极具代表的网络结构之一,在图像处理领域取得了很大的成功。CNN相较于传统的图像处理算法的优点之一在于,避免了对图像复杂的前期预处理过程(提取人工特征等),可以直接输入原始图像。
CNN中主要有两种类型的网络层,分别是卷积层和池化/采样层。
卷积层的作用是提取图像的各种特征,是卷积核在上一级输入层上通过逐一滑动窗口计算而得,卷积核中的每一个参数都相当于传统神经网络中的权值参数,与对应的局部像素相连接,将卷积核的各个参数与对应的局部像素值相乘之和,(通常还要再加上一个偏置参数),得到卷积层上的结果。
池化层的作用是对原始特征信号进行抽象,从而大幅度减少训练参数,另外还可以减轻模型过拟合的程度。池化/采样的方式通常有以下两种:
- Max-Pooling: 选择Pooling窗口中的最大值作为采样值;
- Mean-Pooling: 将Pooling窗口中的所有值相加取平均,以平均值作为采样值;
LeNet-5
LeNet-5是一种经典的CNN网络结构,其结构如下图:
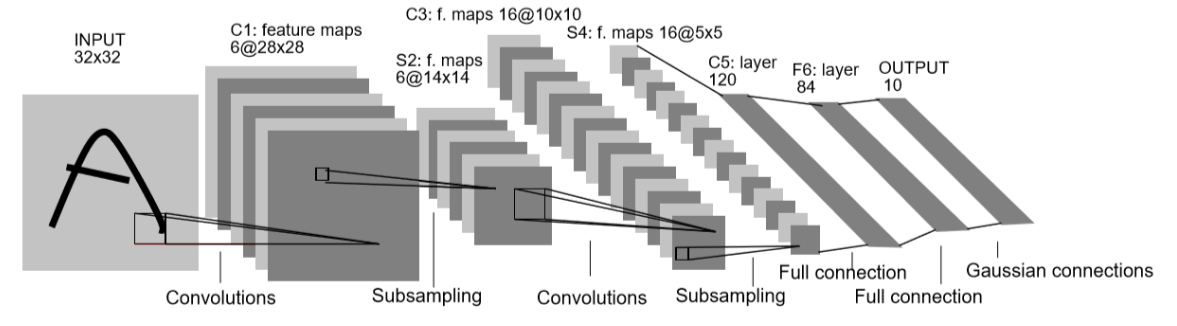
输入层
将输入数据的尺寸统一归一化为$32 \times 32$
卷积层1
使用6个大小为$5 \times 5$的卷积核对输入图像进行第一次卷积运算,得到6个大小为28 * 28的feature map
池化层1
使用$2 \times 2$的核对第一次卷积之后得到的结果进行池化,得到6个$14\times14$的map
卷积层2
对上一层池化得到的输出进行组合,将6个特征增加为16个,使用16种$5\times 5$的卷积核进行卷积操作,得到16个$10\times10$的特征图。特征的组合如下:
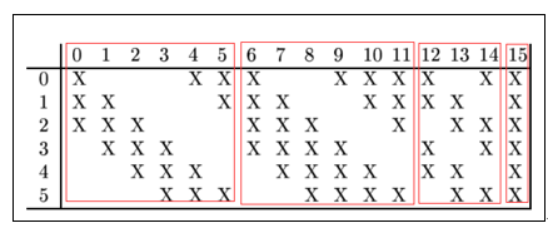
池化层2
对输入的$10\times10$的特征图,使用$2\times2$的核进行池化,得到16个$5\times5$的feature map
卷积层3
使用120种$5\times5$的卷积核进行卷积,输出120个$1\times1$的feature map
全连接层
使用全连接层将上一层输出的120个节点与本层的84个节点进行全连接
输出层
将前一层的84个节点转换为输出的大小(与输出大小进行全连接)
MNIST手写数据集
MNIST数据集是机器学习领域中非常经典的一个数据集,由60000个训练样本和10000个测试样本组成,每个样本都是一张28 * 28像素的灰度手写数字图片。
图片示例如下:

CIFAR-10数据集
CIFAR-10数据集由10个类的60000个32x32彩色图像组成,每个类有6000个图像。有50000个训练图像和10000个测试图像。
数据集分为五个训练批次和一个测试批次,每个批次有10000个图像。测试批次包含来自每个类别的恰好1000个随机选择的图像。训练批次以随机顺序包含剩余图像,但一些训练批次可能包含来自一个类别的图像比另一个更多。总体来说,五个训练集之和包含来自每个类的正好5000张图像。
以下是数据集中的类,以及来自每个类的10个随机图像:

具体实现
LeNet5网络搭建
根据上述LeNet5的每一层结构,搭建LeNet5神经网络
1 | class leNet5(nn.Module): |
MNIST手写数据集测试
相关参数设置
1 | input_size = 28 * 28 |
下载MNIST数据集并进行读取
1 | train_dataset = torchvision.datasets.MNIST(root='./data',train=True, transform=transforms.ToTensor(), download=True) |
损失函数及优化器设计
1 | lossFunction = nn.CrossEntropyLoss() |
训练网络
1 | for epoch in range(num_epochs): |
CIFAR-10数据集测试
相关参数设置
1 | input_size = 32 * 32 |
下载数据集并进行读取
1 | train_dataset = torchvision.datasets.CIFAR10(root='./data',train=True, transform=transforms.ToTensor(), download=True) |
损失函数及优化器设计
由于CIFAR-10数据集与MNIST相比更为复杂,因此使用Adam作为优化器,实验证明识别率确实比SGD更高
1 | lossFunction = nn.CrossEntropyLoss() |
网络训练部分与MNIST类似