索引
顺序索引:基于值的顺序排序
散列索引:基于将值平均分布到若干散列桶中
聚集索引(clustering index)or 主索引(primary index):如果包含记录的文件按照某个搜索码指定的顺序排序,那么该搜索码对应的索引称为聚集索引。聚集索引的搜索码常常是主码,尽管并非必须如此。
非聚集索引(nonclustering index)or 辅助索引(secondary index):搜索码指定的顺序与文件中记录的物理顺序不同的索引称为非聚集索引
稠密索引(dense index):在稠密索引中,文件中的每个搜索码值都有一个索引项。在稠密非聚集索引中,索引必须存储指向所有具有相同搜索码值的记录的指针列表。
稀疏索引(sparse index):在稀硫索引中,只为搜索码的某些值建立索引项,只有索引是聚集索引时才能使用稀疏索引。
B+树
叶结点最多有 $n-1$ 个值,最少有 $\lceil (n-1)/2\rceil$ 个值
非叶节点最多可容纳 $n$ 个指针,最少必须有 $\lceil n/2\rceil$ 个指针
insertion

insert “Adams”:
insert “Lamport”:
Deletion

delete “Srinivasan”:
delete “Singh” and “Wu”:
delete “Gold”:
B树
Similar to B+tree, but B-tree allows search-key values to appear only once; eliminates redundant storage of search keys.

- Advantages of B-Tree indices:
➢ May use less tree nodes than a corresponding B+tree (because of duplicate).
➢ Sometimes possible to find search-key value before reaching leaf node. - Disadvantages of B-Tree indices:
➢ Only small fraction of all search-key values are found early
➢ Non-leaf nodes are larger, so fan-out is reduced. Thus B-Trees typically have greater depth than corresponding B+Tree
➢ Insertion and deletion more complicated than in B+Trees
➢ Implementation is harder than B+Trees.
因而许多数据库实现使用B+树
Hash
bucket overflow(桶溢出)处理:
- close addressing:增加溢出桶、溢出链,用来存储溢出部分
- open addressing:溢出部分放到别的桶中(无溢出链)
Dynamic Hashing 动态散列
extendable hashing 可扩充散列
https://www.cnblogs.com/kegeyang/archive/2012/04/05/2432608.html
Index Definition in SQL
1 | create index <index-name> on <table-name> (<attribute-list>) |
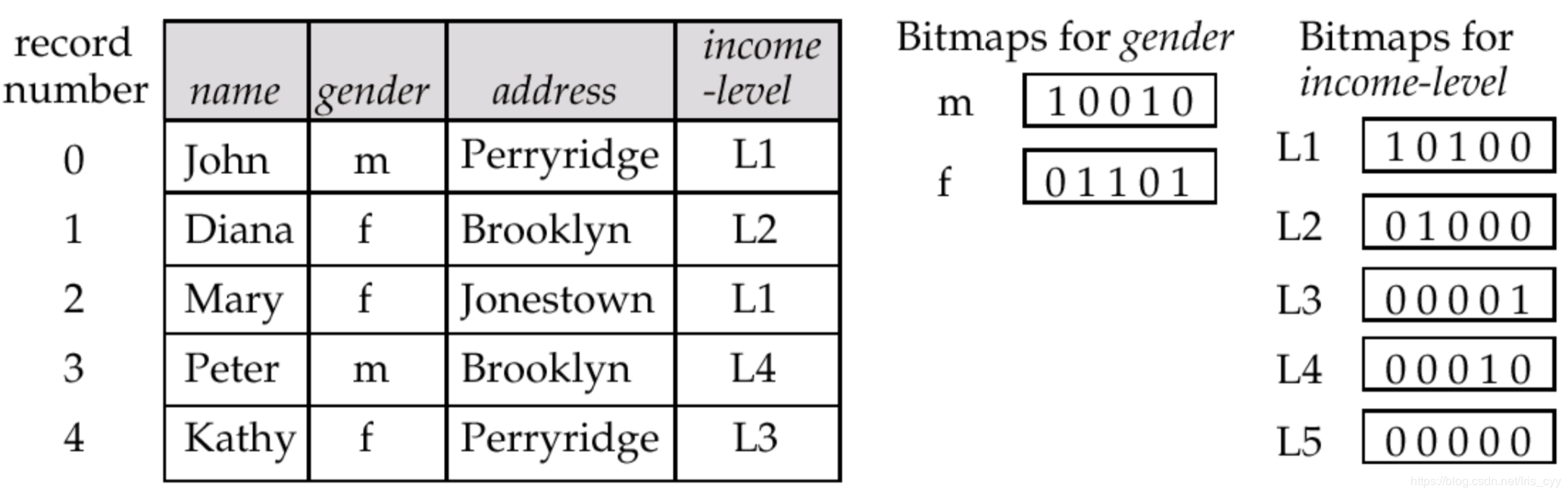
Bitmap Indices