有序容器(不可变):字符串(string)、元组(tuple)、列表(list)
无序容器(可变):集合、字典
序列(Sequence)
不是数据结构,是容器的一种
下标从0开始
字符串:’hello’
列表:[‘h’, ‘e’, ‘l’, ‘l’, ‘o’]
元组:(‘h’, ‘e’, ‘l’, ‘l’, ‘o’)
所有序列类型都可以进行如下操作:
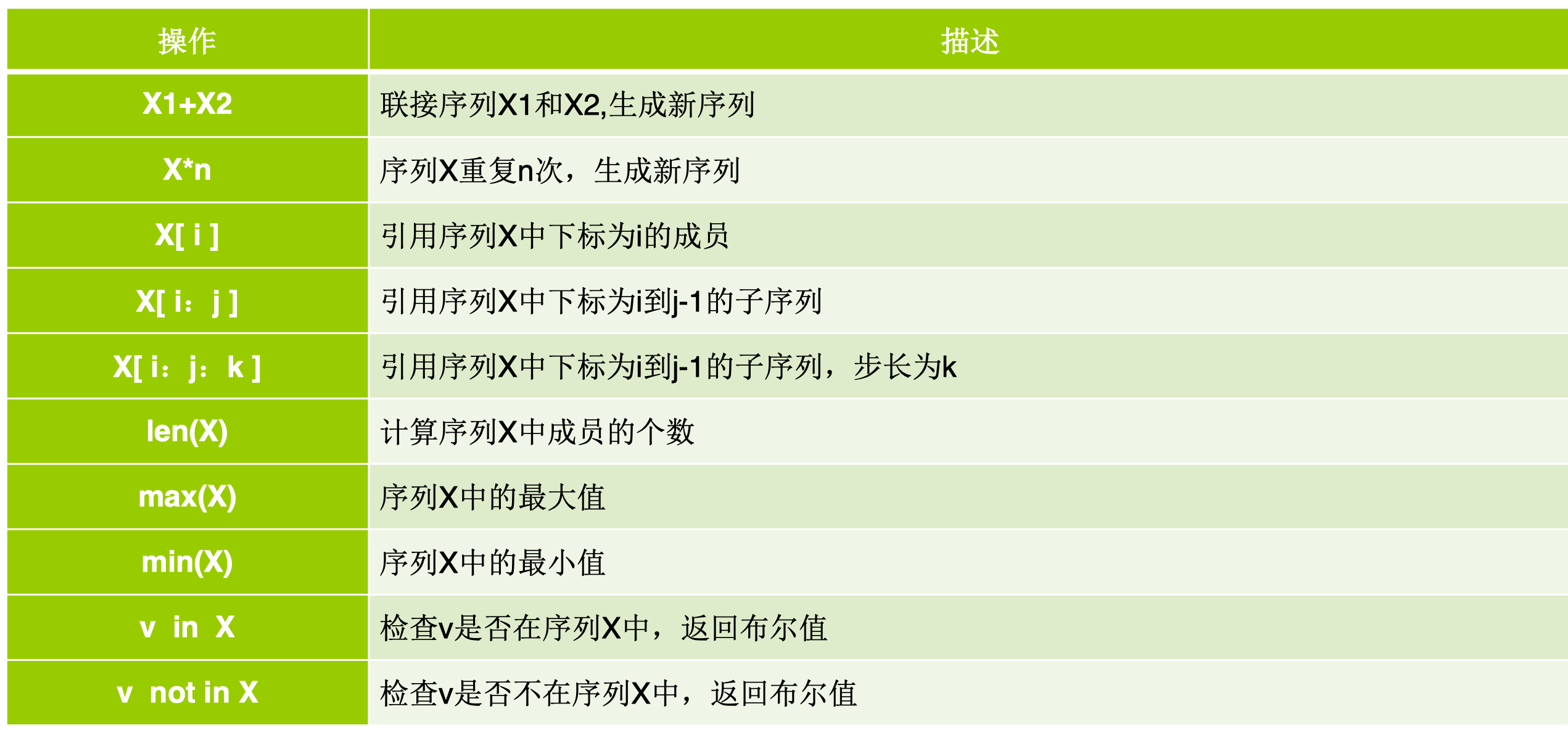
切片
<list> [<begin> : <end> : <step>]
如果切片中使用负值访问,表示倒数第几个(如a[1:-3],表示第1到倒数3(不含)—> 最后一个元素是-1)
值为0可以省略(如a[:4])
end可以大于序列长度(就只切长度内的部分)
a[::-1] 可用来倒序(或者可以用a.reverse())
a[::2] 间隔为2的切片
1 | a = [12,2,3,5,6] |
a[:] 从头到尾切
复制
如果将一个序列变量赋值给另外一个变量,则这2个变量表达了同一个序列。
1 | a = [2, 3, 5, 7, 11, 13] |
如果希望2个变量各自拥有独立的序列,可使用切片
1 | a = [2, 3, 5, 7, 11, 13] |
运算
+用来连接两个序列
1 | a = [2, 3, 5, 7, 11, 13] |
*用于重复
1 | [1,2,3]*3 |
in判断序列中是否有特定值
1 | a = [2,3,5,7,11,13] |
len()函数返回序列内部元素的个数
min()和max()函数计算序列中的最小值和最大值(字符串的大小是按照其Unicode 编码来比较)
其他操作
1 | list.index(x, begin, end) #返回x在list中的下标 |
注意,find只能用于str,不能用于list
Random.shuffle() 打乱原列表中元素的顺序
sort() 用来直接排序,不返回(a.sort()即可)
replace 返回替代完后的值,不改变原列表(s = s.replace(‘a’, ‘b’))
remove 删除第一个值是这样的元素(在原列表中改)
1 | a = ['1', '2', '3', '1'] |
pop() 返回list的最后一个元素,并将其在list里面去掉
random.randint(x, y) 生成x,y区间内的随机数(包含x和y)
字符串
单引号和双引号没有区别
当在双引号” “内部还需要使用引号时,可以使用单引号 ’ ’,当在单引号’ ’ 内部需要使用引号时,可以使用双引号” “
用s[i]访问字符串s中的第i个字符,i=-1时访问最后一个字符
子串:s[m:n],访问第m到第n-1组成的子串
不以\0作为字符串结尾
\用作转义,\v纵向制表符,\r回车,\f换页
用三引号时可以在字符串内部换行
1 | print("""hello |
或者可以用\在字符串内部换行,但与三引号不同的是,输出不随之换行,只能用来处理长字符串
1 | print("hello\ |
+连接两个字符串(必须两个都是str,不能是其他如int等)
*用复制一个字符串若干次形成新的字符串(*后面的必须是整数)
1 | 'ab'*2 |
比大小,从前往后按位比,’a’<’b’,’A’<’a’
在一个字符串字面量前加一个字符r,表示这个字符串是原始字符串,其中的\不被当作是转义字符前缀。
1 | s = r'hello\nworld' #相当于s='hello\\nworld' |
字符串不可修改(元素赋值,切片赋值都是非法的),字符串中的数据(字符)是不能修改的。
1 | s = 'hello' |
可以通过用新的字符串对变量重新赋值,表示新的字符串。
1 | s = 'hello' |
一些函数:
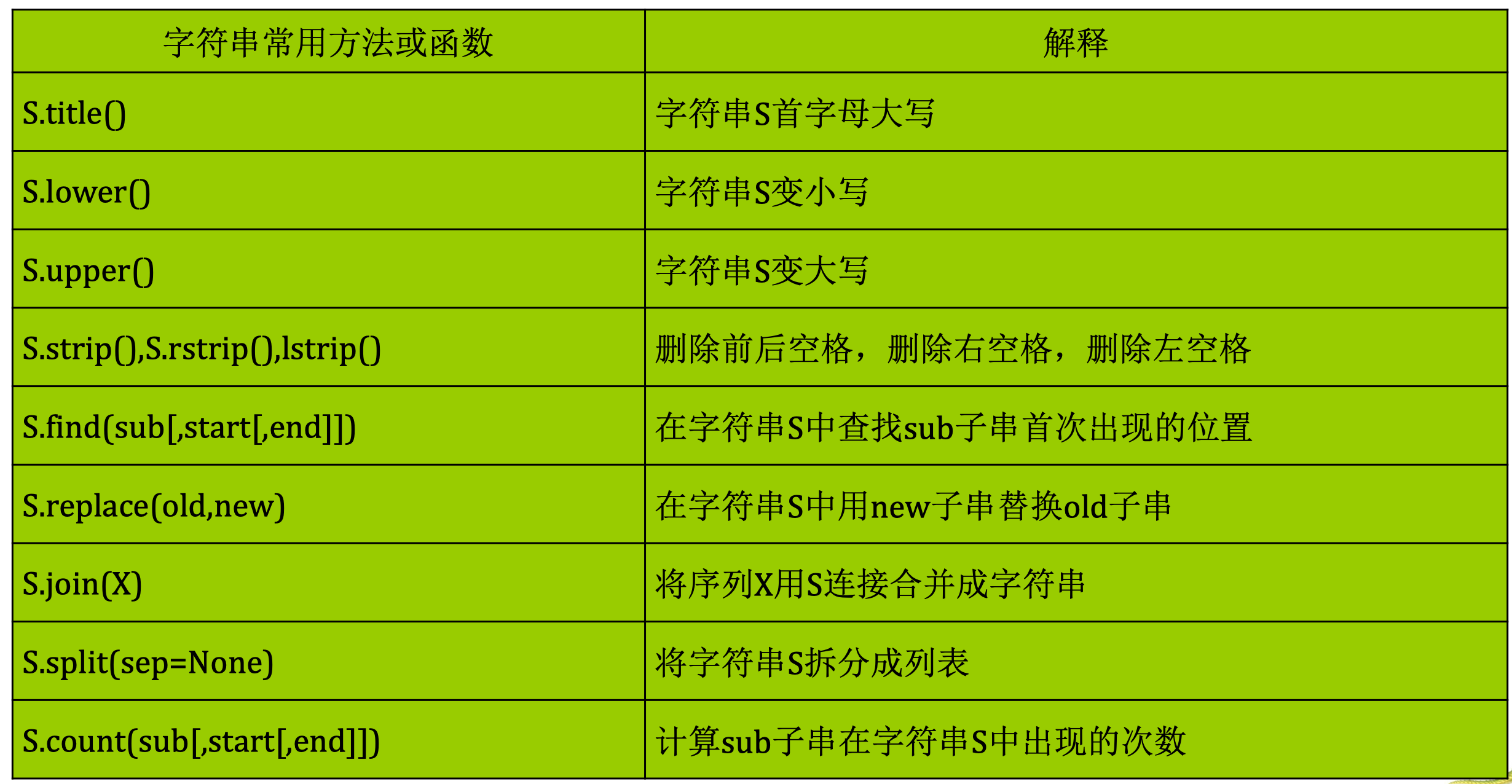
s.replace(old, new):把字符串s中的所有子串old都替换成new
find(): 在字符串中查找子串,返回第一次出现的位置下标(从0开始),如果找不到返回-1
可以指定查找范围
1 | s = 'This is a test.' |
替换多个单字符:translate()
1 | table = str.maketrans ('abc','zyx') #不要求是连续子串,会把a全部换成z,b全部换成y.. |
加密:A -> C, B -> D, …
2
3
4
5
6
7
pt = string.ascii_uppercase #pt = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
ct = pt[2:] + pt[:2] #ct = 'CDEFGHIJKLMNOPQRSTUVWXYZ' + 'AB'
table = str.maketrans(pt, ct) #一一对应关系,生成转换表
ins = input()
ours = ins.translate(table) #根据table进行转换
print(outs)
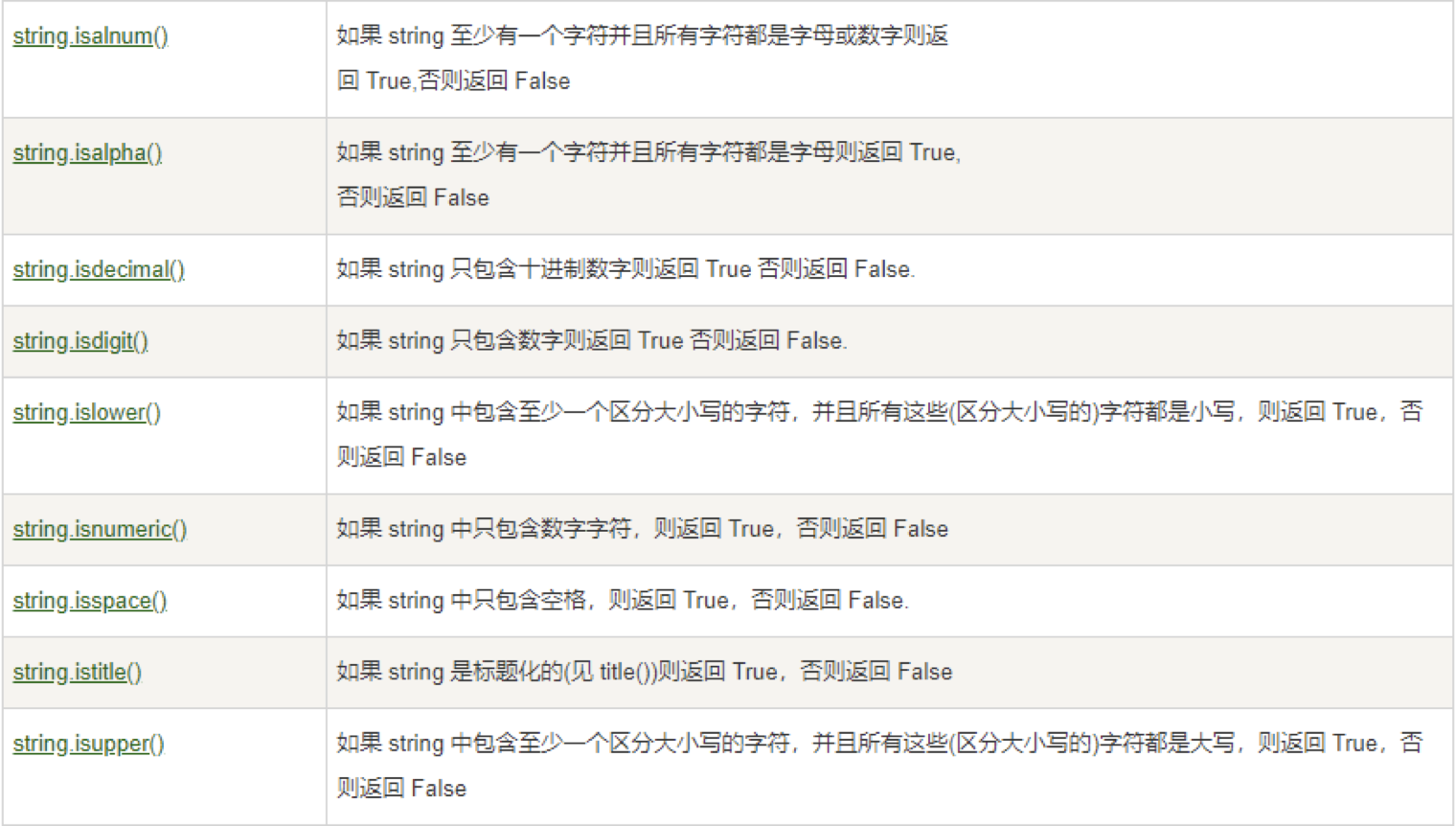
列表
1 | [<expression> for <item> in <iterable>] |
列表中元素可以是不同类型,且元素可以被修改
赋值
单元素
1 | a = [1,3,5,7,9] |
切片赋值
1 | name = list('Perl') |
拷贝
1 | a = [1,2,3,4] |
删除
del name[2]
1 | name = list('Perl') |
1 | a = [2,3,4] |
二维列表
1 | m = [[0,0,0], [0,0,0], [0,0,0], [0,0,0]] |
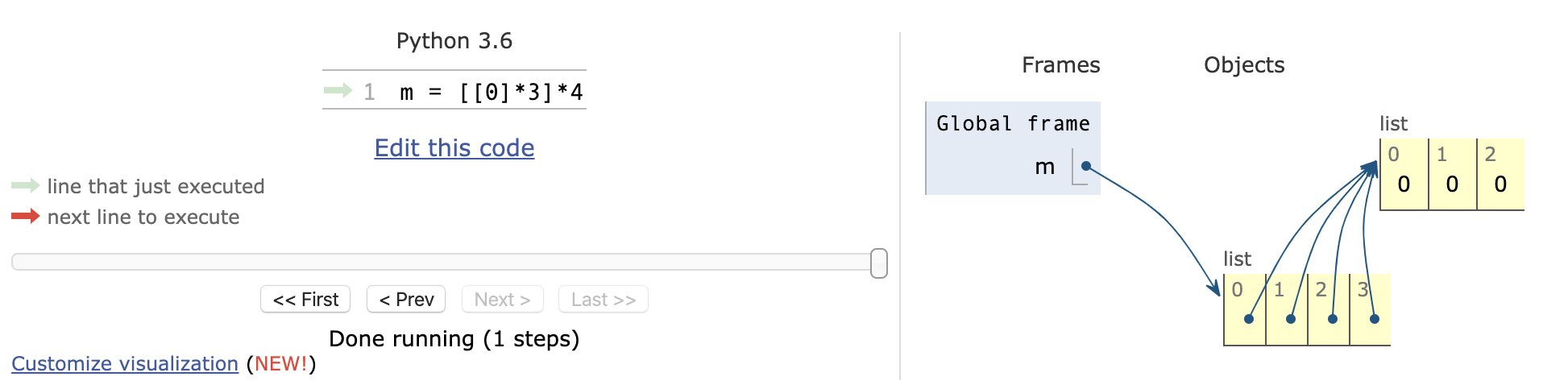
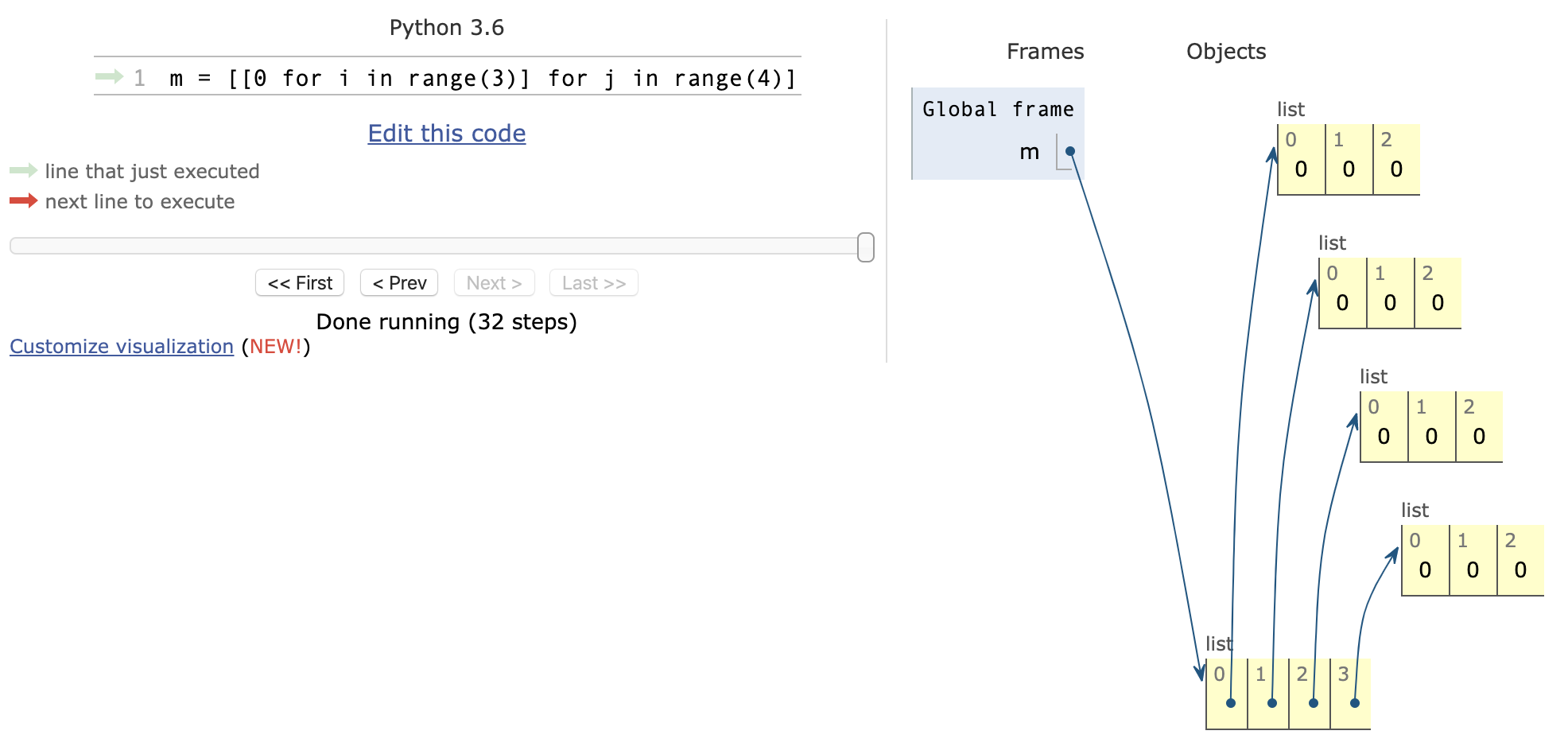
字符串和列表的互相操作
split():拆分字符串
1 | date = '3/11/2018' |
join():将列表中各类型元素组合成一个字符串,元素之间用指定内容填充
1 | a = ['hello','good','boy'] |
元组
可以是任意类型
字面量用()而不是[]
tuple()
1 | a = tuple([2,3,4,5]) |
不可修改!!!!(增加、删除、修改、排序都不可)
T.count(x) 计算x元素出现的次数
T.index(x) 计算x元素第一次出现的下标
速度比列表快
可以作为字典的key或者集合的元素(列表不可)
集合
set()
无序、不重复
可以用{}或者set()来创建(但是空集合必须用set()创建)
集合元素之能是不可变类型
集合的底层是哈希表
1 | a = {'a','b','a','c'} |
集合间运算
1 | a = set('abracadabra') |
s1.issubset(s2)判断s1是否是s2的子集
s2.issuperset(s1)判断是s1是否是s2的超集(子集的反义词是超集)
s1 < s2: s1是s2的真子集
s1 <= s2: s1是s2的子集
s1 > s2: s1是s2的真超集
s1 >= s2: s1是s2的超集

基本操作
添加元素:s.add(x)、s.update(x)
移除元素:s.remove(x)(如果元素不存在会error)、s.discard(x)(如果元素不存在不会error)
随机删除集合中的一个元素:s.pop()
清空:s.clear()
max()获取最大值,min()获取最小值,sum()求和,len()获取集合元素数量
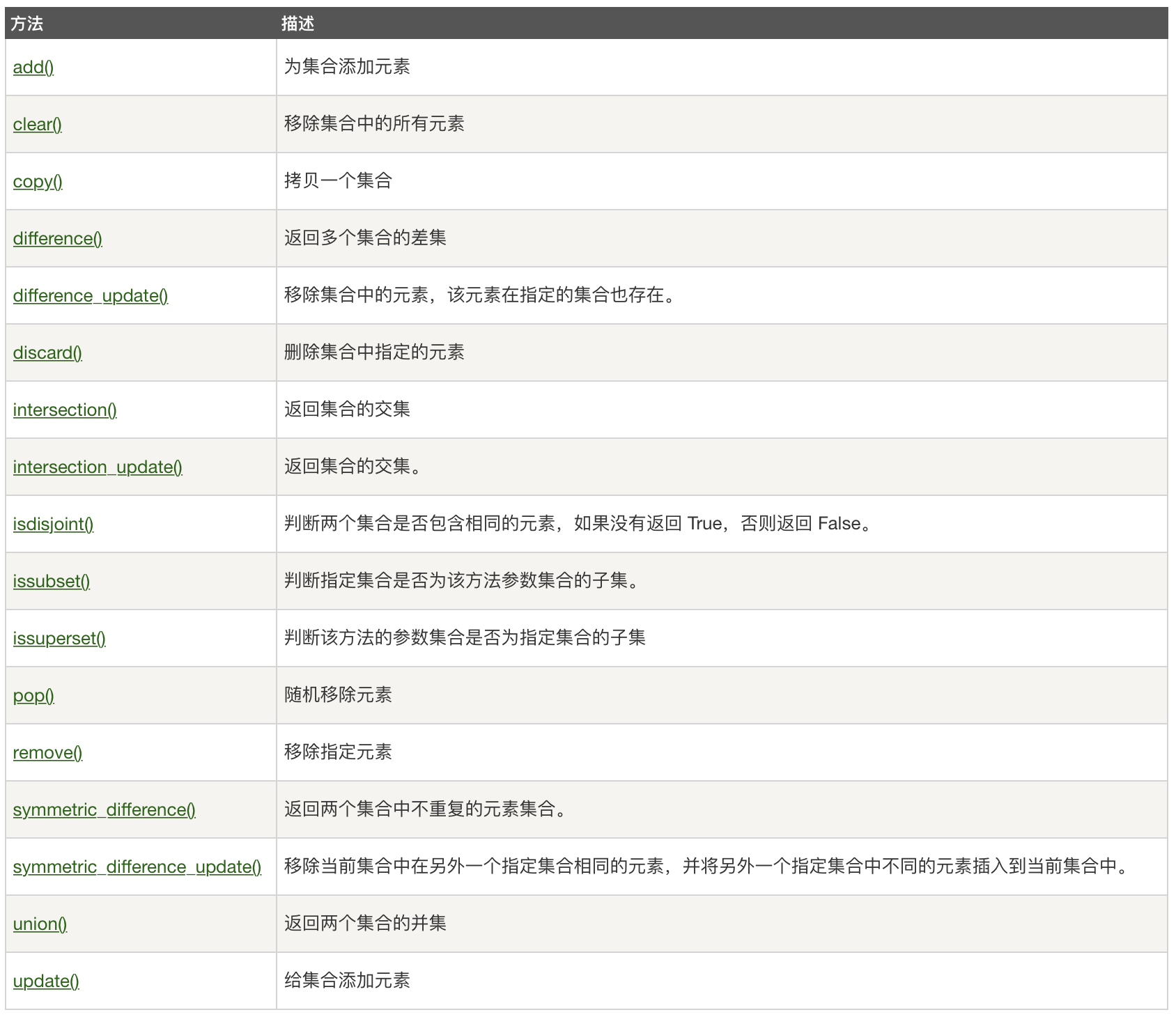
字典
dict() 或者用空的{}创建空的字典
key-value
其中key必须是不可变类型(所以list不可以作为key)
1 | scores = {'语文': 89, '数学': 92, '英语': 93} |
通过key可以访问到value
1 | scores['语文'] |
为不存在的key赋值即会为dict添加键值对
in 和 not in 都是基于key来判断
1 | d = {'a': 1, 'b': 2} |
d.clear() 清空
d.get(‘key’) 通过key获得value
d.update({‘key’ : value}) 更新键值对,可以同时更新多组(如果存在key则更改value,不存在则新建)
items()、keys()、values() 分别用于获取字典中的所有 key-value 对、所有 key、所有 value
1 | cars = {'BMW': 8.5, 'BENS': 8.3, 'AUDI': 7.9} |
pop() 方法用于获取指定 key 对应的 value,并删除这个 key-value 对
1 | cars = {'BMW': 8.5, 'BENS': 8.3, 'AUDI': 7.9} |
popitem() 方法用于随机弹出字典中的一个 key-value 对(事实上是弹出最后一个,但是字典中的顺序不可知)
1 | cars = {'AUDI': 7.9, 'BENS': 8.3, 'BMW': 8.5} |
del可用于删除项
1 | del score['语文'] |
len可以获取字典条目的数量
==和!=比较两个字典是否相同(键和值都相同,和项的顺序无关)
