本次开发的是一个学术搜索引擎,可以根据关键词从数据库中搜索相关内容,实现搜索引擎的基本功能。本程序采用Java程序设计语言,在Eclipse平台下编辑、编译与调试。通过爬虫技术获得来源于ACL学术网站https://www.aclweb.org/anthology/的相关文献信息,基于此建立搜索引擎。
这个搜索引擎项目中用到了Jsoup爬虫、Lucene搜索引擎等技术,也综合了Java的文件读入输出、异常判断、jar包的引用等等。由于整个项目所需要用到的数据集较大,总共有53745篇文献,每一篇都要从bib中读取信息、访问对应url,并下载其中500篇PDF,工作量浩大,整个数据集的获取所需的时间非常长。在整个爬取过程中遇到了很多异常,例如,刚开始爬取的时候,常常会遇到连接超时或者读取超时的问题导致程序终止;在访问的过程中发现bib文件所提供的url链接有多种格式,有一些是网页,而另一些是PDF链接。在查找了资料之后,逐一解决了这些问题。编写代码延长判定“timeout”的时长,并让访问失败时尝试再次访问而不会直接退出并终止。同时在终止程序时输出终止的位置(已访问的数量),下一次可以手动设置爬取的起点,不用每次都从头开始。
设计说明
具体实现的功能如下:
解析包含53745篇文献基本信息的BibText格式文件,得到文献结构化信息,如标题、作者等。
根据BibText中所给的URL链接,访问文献元数据网页,使用Jsoup工具抓取摘要等其它在BibText中未包含的信息
从文献元数据网页上访问下载PDF文件的链接,并下载PDF文件
利用Lucene为扩充后的详细信息中各字段建立索引
建立搜索引擎,用户通过命令行进行交互,根据提示输入要检索的字段以及关键词,获得相关程度排序最高的5篇文献,将这5篇文献的标题、作者、网页链接依次输出在命令行。
项目中使用的jar包如下所示:
IKAnalyzer2012_FF.jar
jsoup-1.12.1.jar
lucene-core-4.10.0.jar
lucene-queries-4.10.0.jar
lucene-queryparser-4.10.0.jar
总体设计
功能模块设计
本程序需实现的主要功能有:
解析bib文件,提取标题、作者等基本信息
根据从bib中提取得到的文献元数据链接,访问网页并获取详细信息
从元数据链接中访问PDF下载链接,下载指定文献的PDF文档
根据文献详细信息的各字段建立索引
建立搜索引擎,根据用户输入的字段类别和关键字,搜索相关信息
程序的总体功能如图1所示:

流程图设计
程序总体流程如图2所示:

详细设计
BibText解析
在anthology.bib文件中,汇总了53745篇文献的基本信息,格式如下:
1 | @inproceedings{sanacore-etal-2019-semantic, |
根据格式进行读取,具体方法如下:
若读入行的第一个字符为“@”,表示一个新的文献开始
若读入行的第一个字符为“}”,表示一个文献结束
在bib中的信息中,只需要获取并存储title, author, url字段的内容。因为除了title和author之外的信息,都在网页中得到显示,并且存储格式一致,直接从网页中爬取较为方便。其中需要注意的是,一篇文章可能有多个作者,多作者的信息在bib文件中分行存储。在进行读取时,将分行的信息合并为同一个字段内容进行存储。
Jsoup爬虫
根据从bib文件中获取的url信息,访问文献所在链接,并利用Jsoup工具对页面进行解析。
需要注意的是,bib中的url信息分为两部分,一部分为网页的元数据链接,另一部分为以“http://doi.org/”开头的PDF下载链接。对于前一部分url,使用Jsoup工具访问链接之后爬取信息;而对于后一部分url,链接指提供下载功能,因此直接使用bib中信息建立索引,若在下载范围内,则访问链接进行下载。
考虑到可能会存在连接超时导致访问失败的问题,在代码中进行解决。思路是,如果访问失败,将停顿1s之后再次尝试访问。如果对该链接访问失败次数达到20次,说明可能是网络存在问题,将输出异常信息,并输出当前正在进行爬取的链接的编号(1-53745),方便下一次继续爬取(下一次只需要从当前出错的位置开始继续爬取即可,不必从头开始)。
这部分的实现方式如下:
1 | while(true) { |
完成对网页的解析之后,继续使用Jsoup工具访问网页中存储了相关信息的部分,获得需要的内容。
观察网页源代码结构,示例如下:

含有摘要的文献,结构如下:
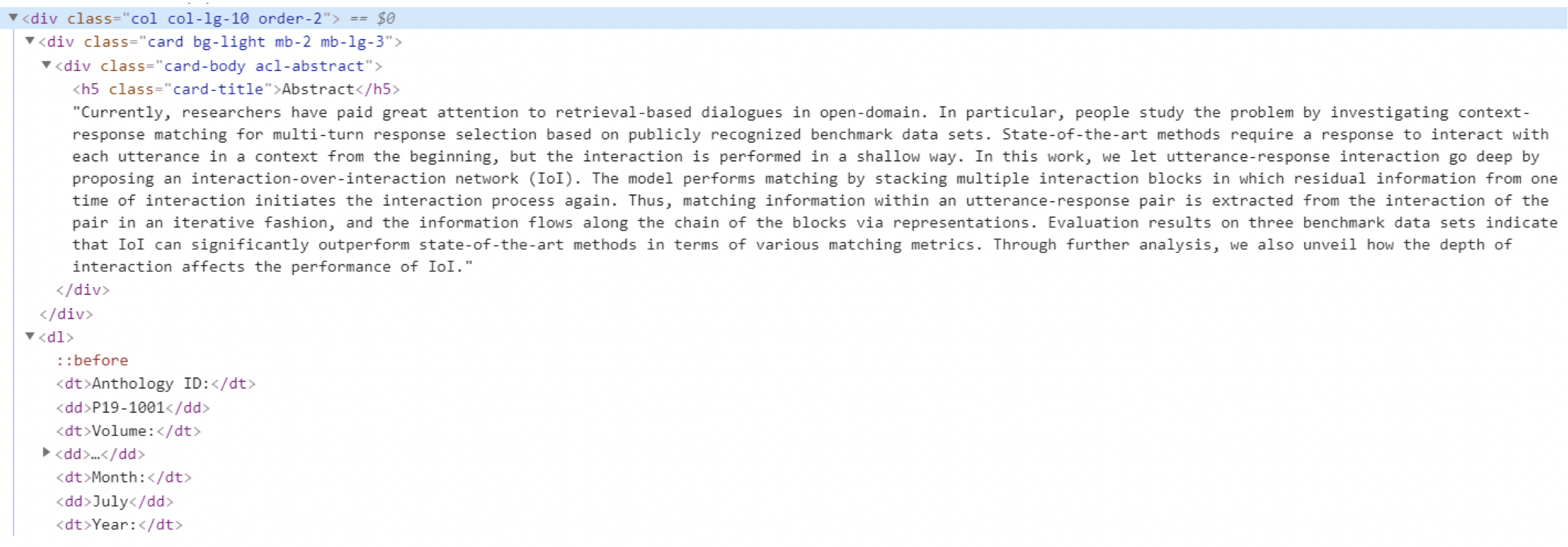
根据此结构,可以编写代码访问并获取相关内容。
使用String类型变量infot和infov分别存储当前获得的字段属性名与属性值,使用Vector<String>类型变量infoType和infoValue分别存储当前文献拥有的全部字段属性以及与之对应的值。
该部分的实现方式如下:
1 | //选择网页中需要的信息所在的位置 |
下载PDF文件
根据bib中获取的url值可以很容易得到对应pdf文件所在的网页链接。编写Download模块通过输出字节流的方式下载对应pdf文件。
Download模块的实现方式如下:
1 | public static byte[] readInputStream(InputStream inputStream) throws IOException { |
搜索引擎
搜索引擎的部分在SearchEngine模块中实现。
在获取网页链接的同时对每个文献的信息创建索引,然后根据输入的字段名和关键词进行查找,输出相关度最高的十条搜索结果的标题、作者和链接。
创建索引的部分原理与格式与demo一致,代码如下:
1 | public static void createIndex(String filePath, Essay essay){ |
搜索部分实现如下:
1 | public static void search(String filePath, String queryStr, String queryField){ |
测试与运行
程序运行
在程序代码基本完成后,经过不断的调试与修改,能够完成上述功能。由于数据量较大,建立数据库的过程耗费了较多时间。最终完成了数据库的建立、PDF文件的下载、搜索引擎的建立,并对搜索引擎的功能进行了测试。
从网页链接爬取数据集并建立索引:

下载PDF:

程序测试
完成索引的建立之后,测试搜索引擎功能如下:
Anthology id
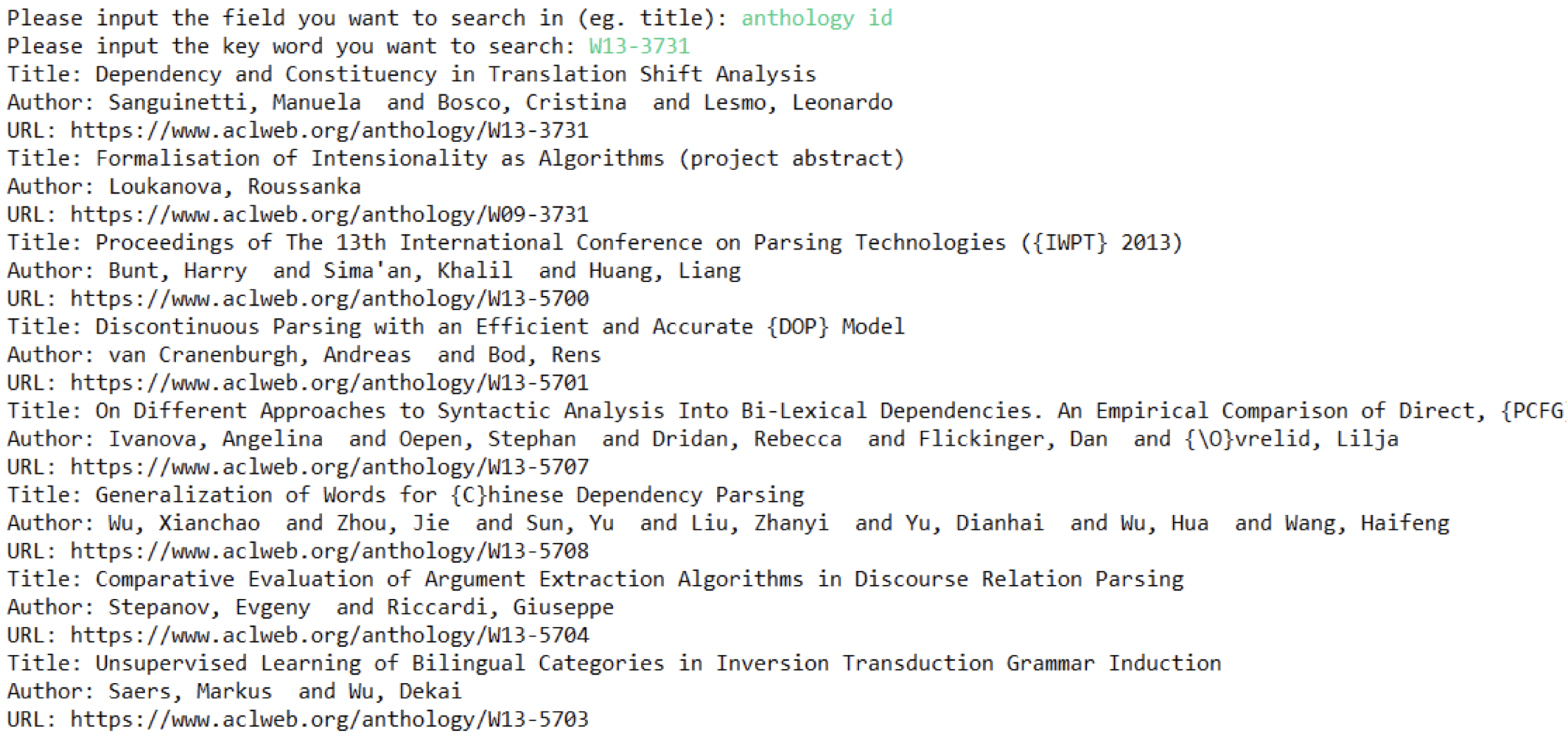
Title

url

完整代码请见github,欢迎star :)